Foile Excel sunt foarte instinctive și ușor de utilizat, ceea ce le face ideale pentru a manipula seturi mari de date chiar și pentru persoanele mai puțin tehnice. Dacă sunteți în căutarea unor locuri pentru a învăța să manipulați și să automatizați lucrurile din fișierele Excel folosind Piton , Nu mai căuta. Sunteți la locul potrivit.
În acest articol, veți învăța cum să utilizați panda pentru a lucra cu foi de calcul Excel. În acest articol vom afla despre:
- Citit Fisier Excel folosind Pandas în Python
- Instalarea și importul Pandas
- Citirea mai multor foi Excel folosind Pandas
- Aplicarea diferitelor funcții Pandas
Citirea fișierului Excel folosind Pandas în Python
Instalarea Pandas
Pentru a instala Pandas în Python, putem folosi următoarea comandă în promptul de comandă:
ce este 10 din 1 milion
pip install pandas>
Pentru a instala Pandas în Anaconda, putem folosi următoarea comandă în Anaconda Terminal:
conda install pandas>
Import Pandas
În primul rând, trebuie să importăm modulul Pandas, care se poate face prin rularea comenzii:
Python3
import> pandas as pd> |
>
>
Fișier de intrare: Să presupunem că fișierul Excel arată așa
Foaia 1:

Foaia 1
Foaia 2:
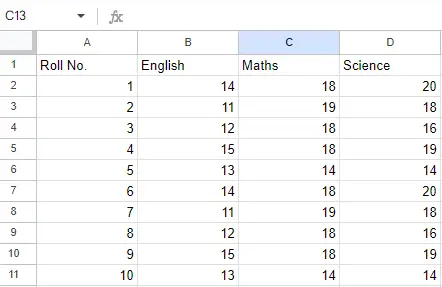
Foaia 2
Acum putem importa fișierul Excel folosind funcția read_excel din Pandas pentru a citi fișierul Excel folosind Pandas în Python. A doua instrucțiune citește datele din Excel și le stochează într-un cadru de date panda, care este reprezentat de variabila newData.
Python3
df>=> pd.read_excel(>'Example.xlsx'>)> print>(df)> |
>
>
Ieșire:
Roll No. English Maths Science 0 1 19 13 17 1 2 14 20 18 2 3 15 18 19 3 4 13 14 14 4 5 17 16 20 5 6 19 13 17 6 7 14 20 18 7 8 15 18 19 8 9 13 14 14 9 10 17 16 20>
Încărcarea mai multor foi folosind metoda Concat().
Dacă există mai multe foi în registrul de lucru Excel, comanda va importa date din prima foaie. Pentru a realiza un cadru de date cu toate foile din registrul de lucru, cea mai ușoară metodă este să creați diferite cadre de date separat și apoi să le concatenați. Metoda read_excel preia argumentul sheet_name și index_col unde putem specifica foaia din care ar trebui să fie format cadrul și index_col specifică coloana de titlu, așa cum se arată mai jos:
Exemplu:
A treia afirmație concatenează ambele foi. Acum, pentru a verifica întregul cadru de date, putem pur și simplu să rulăm următoarea comandă:
Python3
file> => 'Example.xlsx'> sheet1>=> pd.read_excel(>file>,> >sheet_name>=> 0>,> >index_col>=> 0>)> sheet2>=> pd.read_excel(>file>,> >sheet_name>=> 1>,> >index_col>=> 0>)> # concatinating both the sheets> newData>=> pd.concat([sheet1, sheet2])> print>(newData)> |
>
>
Ieșire:
Roll No. English Maths Science 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 6 19 13 17 7 14 20 18 8 15 18 19 9 13 14 14 10 17 16 20 1 14 18 20 2 11 19 18 3 12 18 16 4 15 18 19 5 13 14 14 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Metodele Head() și Tail() în Pandas
Pentru a vizualiza 5 coloane din partea de sus și de jos a cadrului de date, putem rula comanda. Acest cap() și coadă() metoda ia, de asemenea, argumente ca numere pentru numărul de coloane de afișat.
Python3
print>(newData.head())> print>(newData.tail())> |
>
>
Ieșire:
English Maths Science Roll No. 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 English Maths Science Roll No. 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Metoda Shape().
The metoda shape(). poate fi folosit pentru a vizualiza numărul de rânduri și coloane din cadrul de date, după cum urmează:
Python3
newData.shape> |
>
>
Ieșire:
pentru buclă în bash
(20, 3)>
Metoda Sort_values() în Pandas
Dacă vreo coloană conține date numerice, putem sorta acea coloană folosind sort_values() metoda la panda după cum urmează:
Python3
sorted_column>=> newData.sort_values([>'English'>], ascending>=> False>)> |
>
>
Acum, să presupunem că vrem primele 5 valori ale coloanei sortate, putem folosi metoda head() aici:
Python3
sorted_column.head(>5>)> |
>
>
Ieșire:
English Maths Science Roll No. 1 19 13 17 6 19 13 17 5 17 16 20 10 17 16 20 3 15 18 19>
Putem face asta cu orice coloană numerică a cadrului de date, așa cum se arată mai jos:
Python3
newData[>'Maths'>].head()> |
>
>
Ieșire:
Roll No. 1 13 2 20 3 18 4 14 5 16 Name: Maths, dtype: int64>
Metoda Pandas Describe().
Acum, să presupunem că datele noastre sunt în mare parte numerice. Putem obține informații statistice precum media, max, min etc. despre cadrul de date folosind descrie() metoda după cum se arată mai jos:
Python3
newData.describe()> |
>
>
Ieșire:
English Maths Science count 20.00000 20.000000 20.000000 mean 14.30000 16.800000 17.500000 std 2.29645 2.330575 2.164304 min 11.00000 13.000000 14.000000 25% 13.00000 14.000000 16.000000 50% 14.00000 18.000000 18.000000 75% 15.00000 18.000000 19.000000 max 19.00000 20.000000 20.000000>
Acest lucru se poate face și separat pentru toate coloanele numerice folosind următoarea comandă:
Python3
newData[>'English'>].mean()> |
>
>
Ieșire:
14.3>
Alte informații statistice pot fi calculate și folosind metodele respective. Ca și în Excel, se pot aplica și formule, iar coloanele calculate pot fi create după cum urmează:
Python3
newData[>'Total Marks'>]>=> >newData[>'English'>]>+> newData[>'Maths'>]>+> newData[>'Science'>]> newData[>'Total Marks'>].head()> |
cazuri de testare junit
>
>
Ieșire:
Roll No. 1 49 2 52 3 52 4 41 5 53 Name: Total Marks, dtype: int64>
După operarea datelor din cadrul de date, putem exporta datele înapoi într-un fișier Excel folosind metoda to_excel. Pentru aceasta, trebuie să specificăm un fișier Excel de ieșire în care urmează să fie scrise datele transformate, așa cum se arată mai jos:
Python3
newData.to_excel(>'Output File.xlsx'>)> |
>
>
Ieșire:
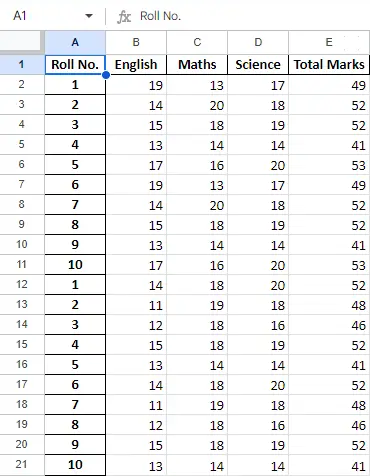
Foaia finală