panda dataframe.corr() este utilizat pentru a găsi corelația perechi a tuturor coloanelor din Pandas Dataframe în Python. Orice NaN valorile sunt excluse automat. Pentru a ignora orice valoare non-numerică, utilizați parametrul numeric_only = True. În acest articol, vom afla despre metoda DataFrame.corr() în Piton .
Sintaxa metodei Pandas DataFrame corr().
Sintaxă: DataFrame.corr(self, method=’pearson’, min_periods=1, numeric_only = False)
Parametri:
- metoda:
- pearson: coeficient de corelație standard
- kendall: coeficientul de corelație Kendall Tau
- spearman: Spearman rank corelation
- min_periods : Numărul minim de observații necesare pe pereche de coloane pentru a avea un rezultat valid. Momentan disponibil numai pentru corelarea pearson și spearman
- numeric_only : dacă se operează sau nu numai valorile numerice. Este setat implicit la Fals.
Se intoarce: count :y : DataFrame
Corelații de date Pandas corr() Metoda
O corelație bună depinde de utilizare, dar este sigur să spunem că aveți cel puțin 0,6 (sau -0,6) pentru a o numi o corelație bună. Un exemplu simplu pentru a arăta cum funcționează corelația Piton .
Python3
import> pandas as pd> df>=> {> >'Array_1'>: [>30>,>70>,>100>],> >'Array_2'>: [>65.1>,>49.50>,>30.7>]> }> data>=> pd.DataFrame(df)> print>(data.corr())> |
teoria arborilor și grafurilor
>
>
Ieșire
Array_1 Array_2 Array_1 1.000000 -0.990773 Array_2 -0.990773 1.000000>
Crearea unui cadru de date eșantion
Imprimarea primelor 10 rânduri ale Dataframe-ului.
Notă: Corelația unei variabile cu ea însăși este 1. Pentru un link către fișierul CSV Utilizat în Cod, faceți clic Aici
Python3
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # Printing the first 10 rows of the data frame for visualization> df[:>10>]> |
>
>
Ieșire

Exemple de metode Python Pandas DataFrame corr().
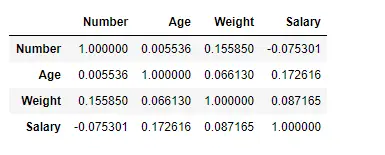
Găsiți corelația între coloane folosind metoda Pearson
Aici, folosim funcția corr() pentru a găsi corelația dintre coloanele din Dataframe folosind metoda „Pearson”. Avem doar patru coloane numerice în Dataframe. Cadrul de date de ieșire poate fi interpretat ca pentru orice celulă, corelația variabilei de rând cu variabila coloană este valoarea celulei. După cum am menționat mai devreme, corelația unei variabile cu ea însăși este 1. Din acest motiv, toate valorile diagonalei sunt 1,00.
Python3
legi de echivalență
# To find the correlation among> # the columns using pearson method> df.corr(method>=>'pearson'>)> |
>
ceva pentru bfs
>
Ieșire
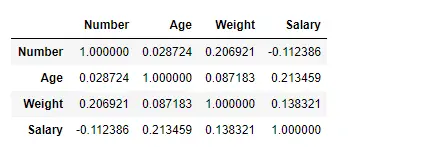
Găsiți corelația între coloane folosind metoda Kendall
Utilizați funcția Pandas df.corr() pentru a găsi corelația dintre coloanele din Dataframe folosind metoda „kendall”. Cadrul de date de ieșire poate fi interpretat ca pentru orice celulă, corelația variabilei de rând cu variabila coloană este valoarea celulei. După cum am menționat mai devreme, corelația unei variabile cu ea însăși este 1. Din acest motiv, toate valorile diagonalei sunt 1,00.
Python3
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # To find the correlation among> # the columns using kendall method> df.corr(method>=>'kendall'>)> |
>
>
Ieșire