BERT, un acronim pentru reprezentările codificatoarelor bidirecționale de la transformatoare , reprezintă o sursă deschisă cadru de învățare automată concepute pentru tărâmul procesarea limbajului natural (NLP) . Originar din 2018, acest cadru a fost creat de cercetătorii de la Google AI Language. Articolul își propune să exploreze arhitectura, funcționarea și aplicațiile BERT .
Ce este BERT?
BERT (Reprezentări codificatoare bidirecționale de la transformatoare) folosește o rețea neuronală bazată pe transformator pentru a înțelege și a genera un limbaj asemănător omului. BERT folosește o arhitectură numai pentru codificator. În original Arhitectura transformatoarelor , există atât module de codificare, cât și module de decodor. Decizia de a utiliza o arhitectură numai codificatoare în BERT sugerează un accent principal pe înțelegerea secvențelor de intrare, mai degrabă decât pe generarea secvențelor de ieșire.
Abordarea bidirecțională a BERT
Modelele tradiționale de limbaj procesează textul secvenţial, fie de la stânga la dreapta, fie de la dreapta la stânga. Această metodă limitează conștientizarea modelului la contextul imediat care precede cuvântul țintă. BERT folosește o abordare bidirecțională luând în considerare atât contextul din stânga cât și din dreapta al cuvintelor dintr-o propoziție, în loc să analizeze textul secvențial, BERT privește simultan toate cuvintele dintr-o propoziție.
Exemplu: malul este situat pe _______ râului.
Într-un model unidirecțional, înțelegerea spațiului liber ar depinde în mare măsură de cuvintele precedente, iar modelul ar putea avea dificultăți în a discerne dacă banca se referă la o instituție financiară sau la malul râului.
BERT, fiind bidirecțional, ia în considerare simultan atât contextul stâng (Malul este situat pe) cât și contextul drept (al râului), permițând o înțelegere mai nuanțată. Acesta înțelege că cuvântul lipsă este probabil legat de locația geografică a băncii, demonstrând bogăția contextuală pe care o aduce abordarea bidirecțională.
Pre-antrenament și reglaj fin
Modelul BERT trece printr-un proces în două etape:
- Pre-instruire pe cantități mari de text neetichetat pentru a învăța înglobările contextuale.
- Reglarea fină a datelor etichetate pentru anumite NLP sarcini.
Pre-instruire pe date mari
- BERT este antrenat în prealabil pe o cantitate mare de date text neetichetate. Modelul învață înglobările contextuale, care sunt reprezentările cuvintelor care iau în considerare contextul înconjurător într-o propoziție.
- BERT se angajează în diferite sarcini nesupravegheate de pre-instruire. De exemplu, s-ar putea să învețe să prezică cuvintele lipsă dintr-o propoziție (Masked Language Model sau sarcină MLM), să înțeleagă relația dintre două propoziții sau să prezică următoarea propoziție dintr-o pereche.
Ajustare fină a datelor etichetate
- După faza de pre-instruire, modelul BERT, înarmat cu înglobările sale contextuale, este apoi ajustat pentru sarcini specifice de procesare a limbajului natural (NLP). Acest pas adaptează modelul la aplicații mai direcționate, adaptând înțelegerea generală a limbajului la nuanțele sarcinii specifice.
- BERT este reglat fin folosind date etichetate specifice sarcinilor din aval de interes. Aceste sarcini ar putea include analiza sentimentelor, răspunsuri la întrebări, recunoașterea entității numite , sau orice altă aplicație NLP. Parametrii modelului sunt ajustați pentru a-și optimiza performanța pentru cerințele specifice ale sarcinii în cauză.
Arhitectura unificată a BERT îi permite să se adapteze la diverse sarcini din aval cu modificări minime, făcându-l un instrument versatil și extrem de eficient în înțelegerea limbajului natural si prelucrare.
Cum funcționează BERT?
BERT este conceput pentru a genera un model de limbaj, astfel încât este utilizat doar mecanismul de codificare. Secvența de jetoane este transmisă codificatorului Transformer. Aceste jetoane sunt mai întâi încorporate în vectori și apoi procesate în rețeaua neuronală. Ieșirea este o secvență de vectori, fiecare corespunzând unui simbol de intrare, oferind reprezentări contextualizate.
Atunci când antrenați modele lingvistice, definirea unui obiectiv de predicție este o provocare. Multe modele prezic următorul cuvânt dintr-o secvență, care este o abordare direcțională și poate limita învățarea contextului. BERT abordează această provocare cu două strategii inovatoare de formare:
- Model de limbaj mascat (MLM)
- Predicția următoarei propoziții (NSP)
1. Mask Language Model (MLM)
În procesul de pre-antrenament al BERT, o porțiune de cuvinte din fiecare secvență de intrare este mascată, iar modelul este antrenat să prezică valorile originale ale acestor cuvinte mascate pe baza contextului oferit de cuvintele din jur.
In termeni simpli,
- Cuvinte de mascare: Înainte ca BERT să învețe din propoziții, ascunde câteva cuvinte (aproximativ 15%) și le înlocuiește cu un simbol special, cum ar fi [MASCA].
- Ghicirea cuvintelor ascunse: Sarcina lui BERT este să descopere care sunt aceste cuvinte ascunse uitându-se la cuvintele din jurul lor. Este ca un joc de a ghici unde lipsesc unele cuvinte, iar BERT încearcă să completeze spațiile libere.
- Cum învață BERT:
- BERT adaugă un strat special peste sistemul său de învățare pentru a face aceste presupuneri. Apoi verifică cât de aproape sunt presupunerile sale de cuvintele ascunse reale.
- Face acest lucru transformându-și presupunerile în probabilități, spunând: „Cred că acest cuvânt este X și sunt atât de sigur de el.
- Atenție specială pentru cuvintele ascunse
- Principalul accent al BERT în timpul antrenamentului este să corecteze aceste cuvinte ascunse. Îi pasă mai puțin de prezicerea cuvintelor care nu sunt ascunse.
- Acest lucru se datorează faptului că adevărata provocare este să identifice părțile lipsă, iar această strategie îl ajută pe BERT să devină foarte bun în înțelegerea sensului și contextului cuvintelor.
În termeni tehnici,
- BERT adaugă un strat de clasificare peste ieșirea de la codificator. Acest strat este crucial pentru prezicerea cuvintelor mascate.
- Vectorii de ieșire din stratul de clasificare sunt înmulțiți cu matricea de încorporare, transformându-i în dimensiunea de vocabular. Acest pas ajută la alinierea reprezentărilor prezise cu spațiul de vocabular.
- Probabilitatea fiecărui cuvânt din vocabular este calculată folosind Funcția de activare SoftMax . Acest pas generează o distribuție de probabilitate pe întregul vocabular pentru fiecare poziție mascata.
- Funcția de pierdere utilizată în timpul antrenamentului ia în considerare doar predicția valorilor mascate. Modelul este penalizat pentru abaterea dintre predicțiile sale și valorile reale ale cuvintelor mascate.
- Modelul converge mai lent decât modelele direcționale. Acest lucru se datorează faptului că, în timpul antrenamentului, BERT este preocupat doar de prezicerea valorilor mascate, ignorând predicția cuvintelor nemascate. Conștientizarea sporită a contextului obținută prin această strategie compensează convergența mai lentă.
2. Predicția următoarei propoziții (NSP)
BERT prezice dacă a doua propoziție este conectată la prima. Acest lucru se face prin transformarea ieșirii jetonului [CLS] într-un vector în formă de 2×1 utilizând un strat de clasificare și apoi calculând probabilitatea ca a doua propoziție să o urmeze pe prima folosind SoftMax.
- În procesul de instruire, BERT învață să înțeleagă relația dintre perechile de propoziții, prezicând dacă a doua propoziție urmează pe prima din documentul original.
- 50% dintre perechile de intrare au a doua propoziție ca propoziție ulterioară în documentul original, iar celelalte 50% au o propoziție aleasă aleatoriu.
- Pentru a ajuta modelul să facă distincția între perechile de propoziții conectate și deconectate. Intrarea este procesată înainte de a intra în model:
- Un simbol [CLS] este inserat la începutul primei propoziții, iar un simbol [SEP] este adăugat la sfârșitul fiecărei propoziții.
- O propoziție încorporată care indică Propoziția A sau Propoziția B este adăugată la fiecare simbol.
- O încorporare pozițională indică poziția fiecărui jeton în secvență.
- BERT prezice dacă a doua propoziție este conectată la prima. Acest lucru se face prin transformarea ieșirii jetonului [CLS] într-un vector în formă de 2×1 utilizând un strat de clasificare și apoi calculând probabilitatea ca a doua propoziție să o urmeze pe prima folosind SoftMax.
În timpul antrenamentului modelului BERT, Masked LM și Next Sentence Prediction sunt antrenate împreună. Modelul își propune să minimizeze funcția de pierdere combinată a Masked LM și Next Sentence Prediction, conducând la un model de limbaj robust, cu capacități îmbunătățite de înțelegere a contextului din propoziții și a relațiilor dintre propoziții.
De ce să antrenați împreună Masked LM și Next Sentence Prediction?
Masked LM ajută BERT să înțeleagă contextul dintr-o propoziție și Predicția următoarei propoziții ajută BERT să înțeleagă legătura sau relația dintre perechile de propoziții. Prin urmare, antrenarea ambelor strategii împreună asigură că BERT învață o înțelegere largă și cuprinzătoare a limbajului, captând atât detaliile din propoziții, cât și fluxul dintre propoziții.
Arhitecturi BERT
Arhitectura BERT este un encoder cu transformator bidirecțional multistrat, care este destul de similar cu modelul transformatorului. O arhitectură de transformator este o rețea de codificator-decodor care utilizează autoatenție pe partea decodorului și atenție pe partea decodorului.
- BERTBAZAare 1 2 straturi în stiva de codificatori în timp ce BERTMAREare 24 de straturi în stiva Encoder . Acestea sunt mai mult decât arhitectura Transformer descrisă în lucrarea originală ( 6 straturi de codificator ).
- Arhitecturile BERT (BASE și LARGE) au, de asemenea, rețele feedforward mai mari (768 și, respectiv, 1024 de unități ascunse) și mai multe capete de atenție (12 și respectiv 16) decât arhitectura Transformer sugerată în lucrarea originală. Contine 512 unități ascunse și 8 capete de atenție .
- BERTBAZAconține 110M de parametri în timp ce BERTMAREare 340M parametri.

Arhitectura BERT BASE și BERT LARGE.
Acest model ia CLS mai întâi simbolul ca intrare, apoi este urmat de o secvență de cuvinte ca intrare. Aici CLS este un simbol de clasificare. Apoi transmite intrarea la straturile de mai sus. Se aplică fiecare strat autoatenție și transmite rezultatul printr-o rețea de tip feedforward, după care transmite următorul codificator. Modelul produce un vector de dimensiune ascunsă ( 768 pentru BAZĂ BERT). Dacă dorim să scoatem un clasificator din acest model, putem lua ieșirea corespunzătoare jetonului CLS.
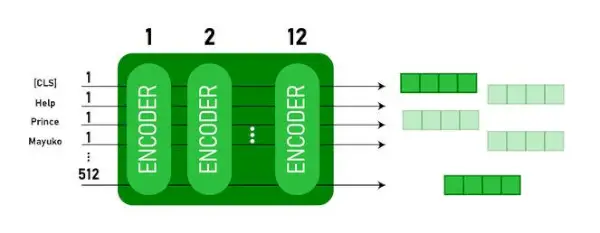
Ieșire BERT ca încorporare
Acum, acest vector antrenat poate fi folosit pentru a efectua o serie de sarcini, cum ar fi clasificarea, traducerea etc. De exemplu, lucrarea obține rezultate excelente doar folosind un singur strat Retea neurala pe modelul BERT în sarcina de clasificare.
Cum se utilizează modelul BERT în NLP?
BERT poate fi utilizat pentru diverse sarcini de procesare a limbajului natural (NLP), cum ar fi:
1. Sarcina de clasificare
- BERT poate fi folosit pentru sarcini de clasificare precum analiza sentimentelor , scopul este de a clasifica textul în diferite categorii (pozitiv/negativ/neutru), BERT poate fi folosit prin adăugarea unui strat de clasificare în partea de sus a ieșirii Transformer pentru jetonul [CLS].
- Indicatorul [CLS] reprezintă informațiile agregate din întreaga secvență de intrare. Această reprezentare grupată poate fi apoi utilizată ca intrare pentru un strat de clasificare pentru a face predicții pentru sarcina specifică.
2. Răspuns la întrebări
- În sarcinile de răspuns la întrebări, în care modelul este necesar pentru a localiza și marca răspunsul într-o anumită secvență de text, BERT poate fi instruit în acest scop.
- BERT este antrenat pentru a răspunde la întrebări prin învățarea a doi vectori suplimentari care marchează începutul și sfârșitul răspunsului. În timpul antrenamentului, modelul este furnizat cu întrebări și pasaje corespunzătoare și învață să prezică pozițiile de început și de sfârșit ale răspunsului în pasaj.
3. Recunoașterea entității denumite (NER)
- BERT poate fi utilizat pentru NER, unde scopul este de a identifica și clasifica entități (de exemplu, Persoană, Organizație, Data) într-o secvență de text.
- Un model NER bazat pe BERT este antrenat prin luarea vectorului de ieșire al fiecărui jeton din transformator și alimentându-l într-un strat de clasificare. Stratul prezice eticheta de entitate numită pentru fiecare token, indicând tipul de entitate pe care o reprezintă.
Cum să tokenizați și să codificați text folosind BERT?
Pentru a tokeniza și a codifica text folosind BERT, vom folosi biblioteca „transformator” din Python.
Comanda de instalare a transformatoarelor:
!pip install transformers>
- Vom încărca jetonul BERT preantrenat cu un vocabular cu majuscule folosind BertTokenizer.from_pretrained(bert-base-cased) .
- tokenizer.encode(text) tokenizează textul introdus și îl convertește într-o secvență de ID-uri de simbol.
- print(ID-uri de simbol:, codificare) tipărește ID-urile jetonelor obținute după codare.
- tokenizer.convert_ids_to_tokens(encoding) convertește ID-urile tokenului înapoi în token-urile corespunzătoare.
- print(Jetoane:, jetoane) tipărește jetoanele obținute după conversia ID-urilor token-urilor
Python3
from> transformers>import> BertTokenizer> # Load pre-trained BERT tokenizer> tokenizer>=> BertTokenizer.from_pretrained(>'bert-base-cased'>)> # Input text> text>=> 'ChatGPT is a language model developed by OpenAI, based on the GPT (Generative Pre-trained Transformer) architecture. '> # Tokenize and encode the text> encoding>=> tokenizer.encode(text)> # Print the token IDs> print>(>'Token IDs:'>, encoding)> # Convert token IDs back to tokens> tokens>=> tokenizer.convert_ids_to_tokens(encoding)> # Print the corresponding tokens> print>(>'Tokens:'>, tokens)> |
>
>
Ieșire:
Token IDs: [101, 24705, 1204, 17095, 1942, 1110, 170, 1846, 2235, 1872, 1118, 3353, 1592, 2240, 117, 1359, 1113, 1103, 15175, 1942, 113, 9066, 15306, 11689, 118, 3972, 13809, 23763, 114, 4220, 119, 102] Tokens: ['[CLS]', 'Cha', '##t', '##GP', '##T', 'is', 'a', 'language', 'model', 'developed', 'by', 'Open', '##A', '##I', ',', 'based', 'on', 'the', 'GP', '##T', '(', 'Gene', '##rative', 'Pre', '-', 'trained', 'Trans', '##former', ')', 'architecture', '.', '[SEP]']> The tokenizer.encodare metoda adaugă specialul [CLS] – clasificare și [SEP] – separator jetoane la începutul și la sfârșitul secvenței codificate.
Aplicarea BERT
BERT este folosit pentru:
- Reprezentarea textului: BERT este folosit pentru a genera încorporarea cuvintelor sau reprezentarea cuvintelor dintr-o propoziție.
- Recunoașterea entității denumite (NER) : BERT poate fi ajustat pentru sarcini de recunoaștere a entităților cu nume, în care scopul este de a identifica entități, cum ar fi numele de persoane, organizații, locații etc., într-un text dat.
- Clasificarea textului: BERT este utilizat pe scară largă pentru sarcini de clasificare a textului, inclusiv analiza sentimentelor, detectarea spamului și clasificarea subiectelor. A demonstrat performanțe excelente în înțelegerea și clasificarea contextului datelor textuale.
- Sisteme de întrebări-răspuns: BERT a fost aplicat sistemelor de răspuns la întrebări, în care modelul este antrenat să înțeleagă contextul unei întrebări și să ofere răspunsuri relevante. Acest lucru este util în special pentru sarcini precum înțelegerea citirii.
- Traducere automată: Înglobările contextuale ale BERT pot fi valorificate pentru îmbunătățirea sistemelor de traducere automată. Modelul surprinde nuanțele de limbaj care sunt cruciale pentru o traducere corectă.
- Rezumat text: BERT poate fi folosit pentru rezumarea abstractă a textului, unde modelul generează rezumate concise și semnificative ale textelor mai lungi prin înțelegerea contextului și a semanticii.
- AI conversațional: BERT este folosit pentru construirea de sisteme AI conversaționale, cum ar fi chatbot, asistenți virtuali și sisteme de dialog. Abilitatea sa de a înțelege contextul îl face eficient pentru înțelegerea și generarea de răspunsuri în limbaj natural.
- Similaritate semantică: Înglobările BERT pot fi folosite pentru a măsura asemănarea semantică între propoziții sau documente. Acest lucru este valoros în sarcini precum detectarea dublelor, identificarea parafrazelor și regăsirea informațiilor.
BERT vs GPT
Diferența dintre BERT și GPT este următoarea:
| BERT | GPT | |
|---|---|---|
| Arhitectură | BERT este conceput pentru învățarea reprezentării bidirecționale. Folosește un obiectiv de model de limbaj mascat, în care prezice cuvintele lipsă dintr-o propoziție pe baza atât a contextului din stânga cât și din dreapta. | GPT, pe de altă parte, este conceput pentru modelarea limbajului generativ. Acesta prezice următorul cuvânt dintr-o propoziție dat fiind contextul precedent, utilizând o abordare autoregresivă unidirecțională. |
| Obiective pre-antrenament | BERT este pre-antrenat folosind un obiectiv model de limbaj mascat și predicția următoarei propoziții. Se concentrează pe captarea contextului bidirecțional și pe înțelegerea relațiilor dintre cuvintele dintr-o propoziție. | GPT este pre-antrenat pentru a prezice următorul cuvânt dintr-o propoziție, ceea ce încurajează modelul să învețe o reprezentare coerentă a limbajului și să genereze secvențe relevante din punct de vedere contextual. |
| Înțelegerea contextului | BERT este eficient pentru sarcini care necesită o înțelegere profundă a contextului și a relațiilor din cadrul unei propoziții, cum ar fi clasificarea textului, recunoașterea entităților numite și răspunsul la întrebări. | GPT este puternic în generarea de text coerent și relevant din punct de vedere contextual. Este adesea folosit în sarcini creative, sisteme de dialog și sarcini care necesită generarea de secvențe de limbaj natural. |
| Tipuri de sarcini și cazuri de utilizare
| Folosit în mod obișnuit în sarcini precum clasificarea textului, recunoașterea entităților numite, analiza sentimentelor și răspunsul la întrebări. | Aplicat la sarcini precum generarea de text, sisteme de dialog, rezumare și scriere creativă. |
| Reglaj fin vs Învățare cu puține lovituri | BERT este adesea reglat fin pe sarcini specifice din aval cu date etichetate pentru a-și adapta reprezentările pre-antrenate la sarcina în cauză. | GPT este proiectat pentru a efectua o învățare în câteva momente, unde se poate generaliza la sarcini noi cu date minime de antrenament specifice sarcinii. |
Verificați și:
- Clasificarea sentimentelor folosind BERT
- Cum se generează încorporarea Word folosind BERT?
- Model BART pentru completarea automată a textului în NLP
- Clasificarea comentariilor toxice folosind BERT
- Predicția următoarei propoziții folosind BERT
Întrebări frecvente (FAQs)
Î. Pentru ce este folosit BERT?
BERT este folosit pentru realizarea sarcinilor NLP, cum ar fi reprezentarea textului, recunoașterea entităților numite, clasificarea textului, sistemele de întrebări și răspunsuri, traducerea automată, rezumarea textului și multe altele.
Î. Care sunt avantajele modelului BERT?
Modelul lingvistic BERT se remarcă prin pregătirea sa extinsă în mai multe limbi, oferind o acoperire lingvistică largă în comparație cu alte modele. Acest lucru face ca BERT să fie deosebit de avantajos pentru proiectele care nu sunt bazate pe engleză, deoarece oferă reprezentări contextuale robuste și înțelegere semantică într-o gamă variată de limbi, sporindu-și versatilitatea în aplicațiile multilingve.
Î. Cum funcționează BERT pentru analiza sentimentelor?
BERT excelează în analiza sentimentelor prin valorificarea învățării reprezentării sale bidirecționale pentru a surprinde nuanțe contextuale, semnificații semantice și structuri sintactice într-un text dat. Acest lucru permite BERT să înțeleagă sentimentul exprimat într-o propoziție, luând în considerare relațiile dintre cuvinte, rezultând rezultate extrem de eficiente ale analizei sentimentelor.
operatori java
Î. Google se bazează pe BERT?
BERT și RankBrain sunt componente ale algoritmului de căutare Google pentru a procesa interogări și conținutul paginilor web pentru a obține o mai bună înțelegere pentru a îmbunătăți rezultatele căutării.