Învățarea automată este ramura Inteligenţă artificială care se concentrează pe dezvoltarea de modele și algoritmi care permit computerelor să învețe din date și să se îmbunătățească din experiența anterioară, fără a fi programate în mod explicit pentru fiecare sarcină. Cu cuvinte simple, ML învață sistemele să gândească și să înțeleagă ca oamenii, învățând din date.
În acest articol, vom explora diversele tipuri de algoritmi de învățare automată care sunt importante pentru cerințele viitoare. Învățare automată este în general un sistem de antrenament pentru a învăța din experiențele trecute și pentru a îmbunătăți performanța în timp. Învățare automată ajută la prezicerea unor cantități masive de date. Ajută la furnizarea de rezultate rapide și precise pentru a obține oportunități profitabile.
Tipuri de învățare automată
Există mai multe tipuri de învățare automată, fiecare cu caracteristici și aplicații speciale. Unele dintre principalele tipuri de algoritmi de învățare automată sunt următoarele:
ce este exportul în linux
- Învățare automată supravegheată
- Învățare automată nesupravegheată
- Învățare automată semi-supervizată
- Consolidarea învățării
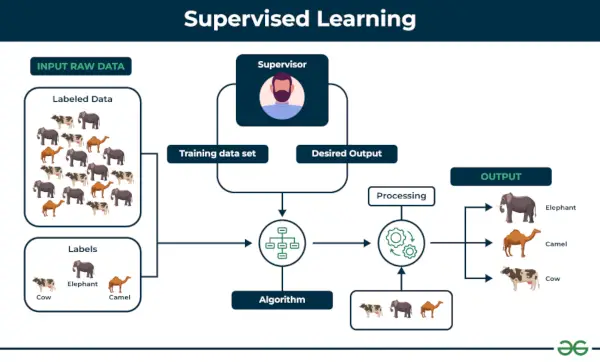
Tipuri de învățare automată
1. Învățare automată supravegheată
Învățare supravegheată este definit ca atunci când un model este antrenat pe a Set de date etichetat . Seturile de date etichetate au atât parametri de intrare, cât și de ieșire. În Învățare supravegheată algoritmii învață să mapeze puncte între intrări și ieșiri corecte. Are atât seturi de date de instruire, cât și de validare etichetate.
Învățare supravegheată
Să-l înțelegem cu ajutorul unui exemplu.
Exemplu: Luați în considerare un scenariu în care trebuie să construiți un clasificator de imagini pentru a diferenția între pisici și câini. Dacă furnizați algoritmului seturile de date cu imagini etichetate de câini și pisici, aparatul va învăța să clasifice între un câine sau o pisică din aceste imagini etichetate. Când introducem noi imagini de câini sau pisici pe care nu le-a văzut niciodată până acum, va folosi algoritmii învățați și va prezice dacă este un câine sau o pisică. Acesta este cum învăţare supravegheată funcționează și aceasta este în special o clasificare a imaginilor.
Există două categorii principale de învățare supravegheată, care sunt menționate mai jos:
- Clasificare
- Regresia
Clasificare
Clasificare se ocupă cu prezicerea categoric variabile țintă, care reprezintă clase sau etichete discrete. De exemplu, clasificarea e-mailurilor ca spam sau nu spam sau prezicerea dacă un pacient are un risc ridicat de boli de inimă. Algoritmii de clasificare învață să mapeze caracteristicile de intrare la una dintre clasele predefinite.
Iată câțiva algoritmi de clasificare:
- Regresie logistică
- Suport Vector Machine
- Pădurea aleatorie
- Arborele de decizie
- K-Cei mai apropiați vecini (KNN)
- Bayes naiv
Regresia
Regresia , pe de altă parte, se ocupă de predicție continuu variabile țintă, care reprezintă valori numerice. De exemplu, estimarea prețului unei case în funcție de dimensiunea, locația și dotările acesteia sau prognozarea vânzărilor unui produs. Algoritmii de regresie învață să mapeze caracteristicile de intrare la o valoare numerică continuă.
arhitectura von neumann
Iată câțiva algoritmi de regresie:
- Regresie liniara
- Regresia polinomială
- Regresia crestei
- Regresia Lasso
- Arborele de decizie
- Pădurea aleatorie
Avantajele învățării automate supravegheate
- Învățare supravegheată modelele pot avea o precizie ridicată pe măsură ce sunt antrenate date etichetate .
- Procesul de luare a deciziilor în modelele de învățare supravegheată este adesea interpretabil.
- Poate fi folosit adesea în modele pre-antrenate, ceea ce economisește timp și resurse atunci când se dezvoltă noi modele de la zero.
Dezavantajele învățării automate supravegheate
- Are limitări în cunoașterea tiparelor și se poate lupta cu tipare nevăzute sau neașteptate care nu sunt prezente în datele de antrenament.
- Poate fi consumatoare de timp și costisitoare, deoarece se bazează pe etichetat numai date.
- Poate duce la generalizări slabe bazate pe date noi.
Aplicații ale învățării supravegheate
Învățarea supravegheată este utilizată într-o mare varietate de aplicații, inclusiv:
- Clasificarea imaginilor : Identificați obiecte, fețe și alte caracteristici din imagini.
- Procesarea limbajului natural: Extrageți informații din text, cum ar fi sentimente, entități și relații.
- Recunoaștere a vorbirii : convertiți limba vorbită în text.
- Sisteme de recomandare : faceți recomandări personalizate utilizatorilor.
- Analize predictive : preziceți rezultate, cum ar fi vânzările, ratarea clienților și prețurile acțiunilor.
- Diagnostic medical : Detectează boli și alte afecțiuni medicale.
- Detectarea fraudei : Identificați tranzacțiile frauduloase.
- Vehicule autonome : Recunoașteți și răspundeți la obiectele din mediu.
- Detectarea spam-ului prin e-mail : Clasificați e-mailurile ca spam sau nu ca spam.
- Controlul calității în producție : Inspectați produsele pentru defecte.
- Scorul de credit : Evaluați riscul ca un împrumutat să nu plătească un împrumut.
- Jocuri : Recunoaște personaje, analizează comportamentul jucătorului și creează NPC-uri.
- Relații Clienți : Automatizați sarcinile de asistență pentru clienți.
- Prognoza Meteo : faceți predicții pentru temperatură, precipitații și alți parametri meteorologici.
- Analiza sportivă : Analizați performanța jucătorului, faceți predicții de joc și optimizați strategiile.
2. Învățare automată nesupravegheată
Învățare nesupravegheată Învățarea nesupravegheată este un tip de tehnică de învățare automată în care un algoritm descoperă modele și relații folosind date neetichetate. Spre deosebire de învățarea supravegheată, învățarea nesupravegheată nu implică furnizarea algoritmului cu rezultate țintă etichetate. Scopul principal al învățării nesupravegheate este adesea acela de a descoperi modele ascunse, asemănări sau grupuri în cadrul datelor, care pot fi apoi utilizate în diverse scopuri, cum ar fi explorarea datelor, vizualizarea, reducerea dimensionalității și multe altele.
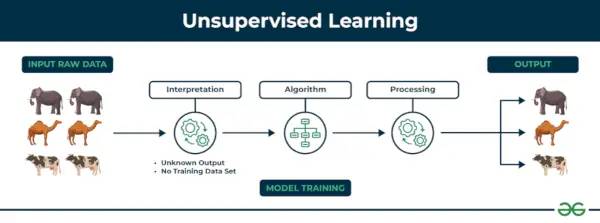
Învățare nesupravegheată
Să-l înțelegem cu ajutorul unui exemplu.
Exemplu: Luați în considerare că aveți un set de date care conține informații despre achizițiile pe care le-ați făcut din magazin. Prin grupare, algoritmul poate grupa același comportament de cumpărare între dvs. și alți clienți, ceea ce dezvăluie clienții potențiali fără etichete predefinite. Acest tip de informații poate ajuta companiile să obțină clienți țintă și să identifice valori aberante.
Există două categorii principale de învățare nesupravegheată, care sunt menționate mai jos:
- Clustering
- Asociere
Clustering
Clustering este procesul de grupare a punctelor de date în clustere pe baza asemănării lor. Această tehnică este utilă pentru identificarea tiparelor și relațiilor în date fără a fi nevoie de exemple etichetate.
Iată câțiva algoritmi de grupare:
- Algoritmul K-Means Clustering
- Algoritmul de schimbare medie
- Algoritmul DBSCAN
- Analiza componentelor principale
- Analiza independentă a componentelor
Asociere
Regula de asociere învață ing este o tehnică de descoperire a relațiilor dintre elementele dintr-un set de date. Identifică reguli care indică prezența unui articol implică prezența unui alt element cu o probabilitate specifică.
Iată câțiva algoritmi de învățare a regulilor de asociere:
- Algoritmul apriori
- Strălucire
- Algoritmul de creștere FP
Avantajele învățării automate nesupravegheate
- Ajută la descoperirea tiparelor ascunse și a diferitelor relații între date.
- Folosit pentru sarcini precum segmentarea clienților, detectarea anomaliilor, și explorarea datelor .
- Nu necesită date etichetate și reduce efortul de etichetare a datelor.
Dezavantajele învățării automate nesupravegheate
- Fără a utiliza etichete, poate fi dificil să se prezică calitatea rezultatelor modelului.
- Interpretabilitatea clusterului poate să nu fie clară și să nu aibă interpretări semnificative.
- Are tehnici precum autoencodere și reducerea dimensionalității care poate fi folosit pentru a extrage caracteristici semnificative din datele brute.
Aplicații ale învățării nesupravegheate
Iată câteva aplicații comune ale învățării nesupravegheate:
- Clustering : Grupați puncte de date similare în grupuri.
- Detectarea anomaliilor : Identificați valori aberante sau anomalii în date.
- Reducerea dimensionalității : Reduceți dimensionalitatea datelor, păstrând în același timp informațiile esențiale.
- Sisteme de recomandare : sugerați produse, filme sau conținut utilizatorilor pe baza comportamentului sau preferințelor lor istorice.
- Modelarea subiectelor : Descoperiți subiecte latente într-o colecție de documente.
- Estimarea densității : Estimați funcția de densitate de probabilitate a datelor.
- Compresie imagini și video : Reduceți cantitatea de stocare necesară pentru conținutul multimedia.
- Preprocesarea datelor : Ajutor la sarcinile de preprocesare a datelor, cum ar fi curățarea datelor, imputarea valorilor lipsă și scalarea datelor.
- Analiza coșului de piață : Descoperiți asocieri între produse.
- Analiza datelor genomice : Identificați modele sau grupați gene cu profiluri de expresie similare.
- Segmentarea imaginii : Segmentează imaginile în regiuni semnificative.
- Detectarea comunității în rețelele sociale : Identificați comunități sau grupuri de persoane cu interese sau conexiuni similare.
- Analiza comportamentului clientului : Descoperiți modele și informații pentru recomandări de marketing și produse mai bune.
- Recomandare de conținut : Clasificați și etichetați conținutul pentru a facilita recomandarea de articole similare utilizatorilor.
- Analiza exploratorie a datelor (EDA) : explorați datele și obțineți informații înainte de a defini sarcini specifice.
3. Învățare semi-supravegheată
Învățare semi-supravegheată este un algoritm de învățare automată care funcționează între supravegheat și nesupravegheat învățând, așa că le folosește pe ambele etichetat și neetichetat date. Este deosebit de util atunci când obținerea de date etichetate este costisitoare, necesită timp sau necesită resurse. Această abordare este utilă atunci când setul de date este costisitor și necesită timp. Învățarea semi-supravegheată este aleasă atunci când datele etichetate necesită abilități și resurse relevante pentru a se instrui sau a învăța din acestea.
Folosim aceste tehnici atunci când avem de-a face cu date puțin etichetate, iar restul mare parte din acestea sunt neetichetate. Putem folosi tehnicile nesupravegheate pentru a prezice etichetele și apoi alimenta aceste etichete la tehnicile supravegheate. Această tehnică este aplicabilă în cea mai mare parte în cazul seturilor de date de imagine unde, de obicei, toate imaginile nu sunt etichetate.
recursiunea în java
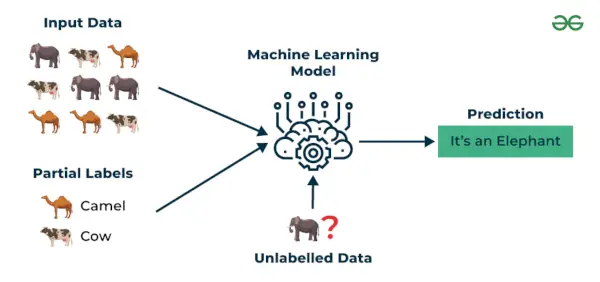
Învățare semi-supravegheată
Să-l înțelegem cu ajutorul unui exemplu.
Exemplu : Luați în considerare că construim un model de traducere lingvistică, a avea traduceri etichetate pentru fiecare pereche de propoziții poate fi consumatoare de resurse. Permite modelelor să învețe din perechile de propoziții etichetate și neetichetate, făcându-le mai precise. Această tehnică a condus la îmbunătățiri semnificative ale calității serviciilor de traducere automată.
Tipuri de metode de învățare semi-supervizate
Există o serie de metode diferite de învățare semi-supravegheată, fiecare cu propriile sale caracteristici. Unele dintre cele mai comune includ:
aliniați imaginea cu css
- Învățare semi-supravegheată bazată pe grafice: Această abordare folosește un grafic pentru a reprezenta relațiile dintre punctele de date. Graficul este apoi folosit pentru a propaga etichete de la punctele de date etichetate la punctele de date neetichetate.
- Propagarea etichetei: Această abordare propagă iterativ etichetele de la punctele de date etichetate la punctele de date neetichetate, pe baza asemănărilor dintre punctele de date.
- Co-instruire: Această abordare antrenează două modele diferite de învățare automată pe diferite subseturi de date neetichetate. Cele două modele sunt apoi folosite pentru a eticheta predicțiile celuilalt.
- Autoinstruire: Această abordare antrenează un model de învățare automată pe datele etichetate și apoi utilizează modelul pentru a prezice etichetele pentru datele neetichetate. Modelul este apoi reantrenat pe datele etichetate și pe etichetele prezise pentru datele neetichetate.
- Rețele adverse generative (GAN) : GAN-urile sunt un tip de algoritm de învățare profundă care poate fi folosit pentru a genera date sintetice. GAN-urile pot fi utilizate pentru a genera date neetichetate pentru învățarea semi-supravegheată prin antrenarea a două rețele neuronale, un generator și un discriminator.
Avantajele învățării automate semi-supervizate
- Conduce la o generalizare mai bună în comparație cu invatare supravegheata, deoarece iau atât date etichetate, cât și neetichetate.
- Poate fi aplicat la o gamă largă de date.
Dezavantajele învățării automate semi-supervizate
- Semi supravegheat metodele pot fi mai complexe de implementat în comparație cu alte abordări.
- Mai necesită ceva date etichetate care ar putea să nu fie întotdeauna disponibile sau ușor de obținut.
- Datele neetichetate pot afecta în consecință performanța modelului.
Aplicații ale învățării semi-supervizate
Iată câteva aplicații comune ale învățării semi-supravegheate:
- Clasificarea imaginilor și recunoașterea obiectelor : Îmbunătățiți acuratețea modelelor combinând un set mic de imagini etichetate cu un set mai mare de imagini neetichetate.
- Procesarea limbajului natural (NLP) : Îmbunătățiți performanța modelelor de limbă și a clasificatoarelor prin combinarea unui set mic de date text etichetate cu o cantitate mare de text neetichetat.
- Recunoaștere a vorbirii: Îmbunătățiți acuratețea recunoașterii vorbirii prin valorificarea unei cantități limitate de date de vorbire transcrise și a unui set mai extins de sunet neetichetat.
- Sisteme de recomandare : Îmbunătățiți acuratețea recomandărilor personalizate prin completarea unui set rar de interacțiuni utilizator-articol (date etichetate) cu o mulțime de date despre comportamentul utilizatorului neetichetate.
- Asistență medicală și imagistică medicală : Îmbunătățiți analiza imaginilor medicale utilizând un set mic de imagini medicale etichetate alături de un set mai mare de imagini neetichetate.
4. Întărirea învățării automate
Întărirea învățării automate algoritmul este o metodă de învățare care interacționează cu mediul prin producerea de acțiuni și descoperirea erorilor. Încercare, eroare și întârziere sunt cele mai relevante caracteristici ale învăţării prin întărire. În această tehnică, modelul continuă să-și mărească performanța folosind Reward Feedback pentru a învăța comportamentul sau modelul. Acești algoritmi sunt specifici unei anumite probleme, de ex. Mașină Google Self Driving, AlphaGo în care un bot concurează cu oamenii și chiar cu el însuși pentru a obține performanțe din ce în ce mai bune în Go Game. De fiecare dată când alimentăm date, ei învață și adaugă datele la cunoștințele lor, care sunt date de antrenament. Deci, cu cât învață mai mult, cu atât este mai bine antrenat și, prin urmare, experimentat.
Iată câțiva dintre cei mai comuni algoritmi de învățare prin întărire:
- Q-learning: Q-learning este un algoritm RL fără model care învață o funcție Q, care mapează stările cu acțiuni. Funcția Q estimează recompensa așteptată de a efectua o anumită acțiune într-o anumită stare.
- SARSA (State-Action-Reward-State-Action): SARSA este un alt algoritm RL fără model care învață o funcție Q. Cu toate acestea, spre deosebire de Q-learning, SARSA actualizează funcția Q pentru acțiunea care a fost efectiv întreprinsă, mai degrabă decât pentru acțiunea optimă.
- Învățare Q profundă : Deep Q-learning este o combinație de Q-learning și deep learning. Deep Q-learning folosește o rețea neuronală pentru a reprezenta funcția Q, ceea ce îi permite să învețe relații complexe între stări și acțiuni.
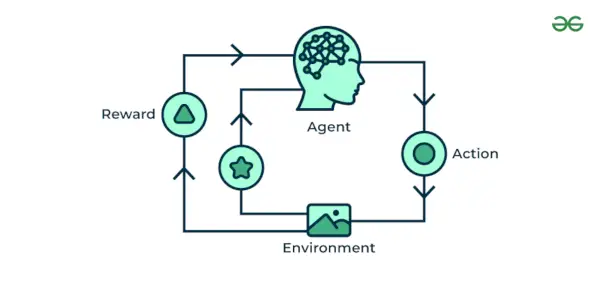
Întărirea învățării automate
Să-l înțelegem cu ajutorul exemplelor.
Exemplu: Consideră că te antrenezi un AI agent să joace un joc precum șahul. Agentul explorează diferite mișcări și primește feedback pozitiv sau negativ în funcție de rezultat. Învățarea prin consolidare găsește, de asemenea, aplicații în care învață să îndeplinească sarcini interacționând cu mediul înconjurător.
Tipuri de întărire Machine Learning
Există două tipuri principale de învățare prin întărire:
Întărire pozitivă
vindeca instrument gimp
- Recompensează agentul pentru a întreprinde o acțiune dorită.
- Încurajează agentul să repete comportamentul.
- Exemple: a oferi un răsfăț unui câine pentru că stă, oferind un punct într-un joc pentru un răspuns corect.
Întărire negativă
- Îndepărtează un stimul nedorit pentru a încuraja un comportament dorit.
- Descurajează agentul să repete comportamentul.
- Exemple: oprirea soneriei puternice atunci când este apăsată o pârghie, evitând o penalizare prin finalizarea unei sarcini.
Avantajele învățării automate de întărire
- Are un proces autonom de luare a deciziilor, care este potrivit pentru sarcini și care poate învăța să ia o secvență de decizii, cum ar fi robotica și jocul.
- Această tehnică este preferată pentru a obține rezultate pe termen lung, care sunt foarte greu de obținut.
- Este folosit pentru a rezolva probleme complexe care nu pot fi rezolvate prin tehnici convenționale.
Dezavantajele învățării automate de întărire
- Întărirea instruirii Agenții de învățare pot fi costisitoare din punct de vedere computațional și consumatoare de timp.
- Învățarea prin întărire nu este de preferat rezolvării unor probleme simple.
- Are nevoie de multe date și de multe calcule, ceea ce îl face nepractic și costisitor.
Aplicații ale învățarii automate de întărire
Iată câteva aplicații ale învățării prin întărire:
- Jocul : RL poate învăța agenții să joace jocuri, chiar și cele complexe.
- Robotică : RL poate învăța roboții să îndeplinească sarcini în mod autonom.
- Vehicule autonome : RL poate ajuta mașinile cu conducere autonomă să navigheze și să ia decizii.
- Sisteme de recomandare : RL poate îmbunătăți algoritmii de recomandare prin învățarea preferințelor utilizatorului.
- Sănătate : RL poate fi folosit pentru a optimiza planurile de tratament și descoperirea medicamentelor.
- Procesarea limbajului natural (NLP) : RL poate fi folosit în sisteme de dialog și chatbot.
- Finanțe și comerț : RL poate fi folosit pentru tranzacționare algoritmică.
- Managementul lanțului de aprovizionare și al stocurilor : RL poate fi folosit pentru a optimiza operațiunile lanțului de aprovizionare.
- Managementul energiei : RL poate fi folosit pentru optimizarea consumului de energie.
- Game AI : RL poate fi folosit pentru a crea NPC-uri mai inteligente și adaptabile în jocurile video.
- Asistenți personali adaptivi : RL poate fi folosit pentru a îmbunătăți asistenții personali.
- Realitate virtuală (VR) și realitate augmentată (AR): RL poate fi folosit pentru a crea experiențe captivante și interactive.
- Control industrial : RL poate fi folosit pentru optimizarea proceselor industriale.
- Educaţie : RL poate fi folosit pentru a crea sisteme de învățare adaptive.
- Agricultură : RL poate fi folosit pentru optimizarea operațiunilor agricole.
Trebuie să verificați, articolul nostru detaliat pe : Algoritmi de învățare automată
Concluzie
În concluzie, fiecare tip de învățare automată își servește propriul scop și contribuie la rolul general în dezvoltarea capacităților îmbunătățite de predicție a datelor și are potențialul de a schimba diverse industrii precum Știința datelor . Ajută la gestionarea producției masive de date și la gestionarea seturilor de date.
Tipuri de învățare automată – Întrebări frecvente
1. Care sunt provocările cu care se confruntă în învățarea supravegheată?
Unele dintre provocările cu care se confruntă învățarea supravegheată includ în principal abordarea dezechilibrelor de clasă, date etichetate de înaltă calitate și evitarea supraadaptării în cazul în care modelele funcționează prost pe datele în timp real.
2. Unde putem aplica învățarea supravegheată?
Învățarea supravegheată este folosită în mod obișnuit pentru sarcini precum analiza e-mailurilor spam, recunoașterea imaginilor și analiza sentimentelor.
3. Cum arată viitorul învățării automate?
Învățarea automată ca o perspectivă viitoare poate funcționa în domenii precum analiza vremii sau climatice, sistemele de sănătate și modelarea autonomă.
4. Care sunt diferitele tipuri de învățare automată?
Există trei tipuri principale de învățare automată:
- Învățare supravegheată
- Învățare nesupravegheată
- Consolidarea învățării
5. Care sunt cei mai comuni algoritmi de învățare automată?
Unii dintre cei mai comuni algoritmi de învățare automată includ:
- Regresie liniara
- Regresie logistică
- Suport mașini vectoriale (SVM)
- K-cei mai apropiați vecini (KNN)
- Arbori de decizie
- Păduri aleatorii
- Rețele neuronale artificiale