În sistemul de operare, a trebuit să dăm intrarea CPU-ului, iar CPU-ul execută instrucțiunile și în final dă ieșirea. Dar a existat o problemă cu această abordare. Într-o situație normală, avem de-a face cu multe procese și știm că timpul necesar în operațiunea I/O este foarte mare în comparație cu timpul necesar CPU pentru execuția instrucțiunilor. Deci, în vechea abordare, un proces va oferi intrarea cu ajutorul unui dispozitiv de intrare, iar în acest timp, procesorul este într-o stare inactivă.
intrarea utilizatorului java
Apoi CPU execută instrucțiunea și ieșirea este din nou dată unui dispozitiv de ieșire și, în acest moment, CPU este, de asemenea, într-o stare inactivă. După afișarea rezultatului, următorul proces își începe execuția. Deci, de cele mai multe ori, procesorul este inactiv, ceea ce este cea mai rea condiție pe care o putem avea în sistemele de operare. Aici intră în joc conceptul de Spooling.
Ce este Spooling-ul
Spooling-ul este un proces în care datele sunt păstrate temporar pentru a fi utilizate și executate de un dispozitiv, program sau sistem. Datele sunt trimise și stocate în memorie sau în alt spațiu de stocare volatil până când programul sau computerul le solicită pentru execuție.
SPOOL este un acronim pentru operațiuni periferice simultane online . În general, spool-ul este menținut în memoria fizică a computerului, în buffer-uri sau în întreruperile specifice dispozitivului I/O. Bobina este procesată în ordine crescătoare, funcționând pe baza unui algoritm FIFO (primul intrat, primul ieșit).
Spooling-ul se referă la punerea datelor diferitelor lucrări I/O într-un buffer. Acest buffer este o zonă specială din memorie sau hard disk care este accesibilă dispozitivelor I/O. Un sistem de operare realizează următoarele activități legate de mediul distribuit:
- Se ocupă de spoolingul datelor dispozitivului I/O, deoarece dispozitivele au rate de acces la date diferite.
- Menține tamponul de spooling, care oferă o stație de așteptare unde datele se pot odihni în timp ce dispozitivul mai lent ajunge din urmă.
- Menține calculul paralel datorită procesului de spool, deoarece un computer poate efectua I/O în ordine paralelă. Devine posibil ca computerul să citească date de pe o bandă, să scrie date pe disc și să scrie pe o imprimantă pe bandă în timp ce își face sarcina de calcul.
Cum funcționează spooling-ul în sistemul de operare
Într-un sistem de operare, spooling-ul funcționează în următorii pași, cum ar fi:
- Spooling-ul implică crearea unui buffer numit SPOOL, care este folosit pentru a reține joburi și date până când dispozitivul în care este creat SPOOL este gata să folosească și să execute acea lucrare sau să opereze pe date.
- Când un dispozitiv mai rapid trimite date către un dispozitiv mai lent pentru a efectua anumite operații, folosește orice memorie secundară atașată ca buffer SPOOL. Aceste date sunt păstrate în SPOOL până când dispozitivul mai lent este gata să opereze pe aceste date. Când dispozitivul mai lent este gata, atunci datele din SPOOL sunt încărcate în memoria principală pentru operațiunile necesare.
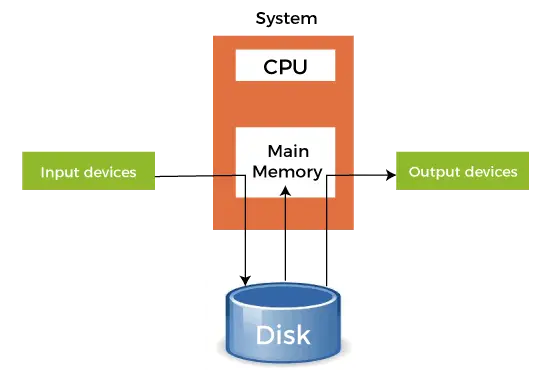
- Spooling-ul consideră întreaga memorie secundară ca un buffer imens care poate stoca multe joburi și date pentru multe operațiuni. Avantajul Spooling-ului este că poate crea o coadă de joburi care se execută în ordinea FIFO pentru a executa joburile unul câte unul.
- Un dispozitiv se poate conecta la multe dispozitive de intrare, ceea ce poate necesita operațiuni asupra datelor lor. Deci, toate aceste dispozitive de intrare își pot pune datele în memoria secundară (SPOOL), care poate fi apoi executată unul câte unul de către dispozitiv. Acest lucru se va asigura că CPU nu este inactiv în orice moment. Deci, putem spune că Spooling este o combinație de buffering și coadă.
- După ce CPU generează o ieșire, această ieșire este mai întâi salvată în memoria principală. Această ieșire este transferată în memoria secundară din memoria principală, iar de acolo, ieșirea este trimisă la dispozitivele de ieșire respective.

Exemplu de spooling
Cel mai mare exemplu de spooling este imprimare . Documentele care urmează să fie tipărite sunt stocate în SPOOL și apoi adăugate la coada pentru tipărire. În acest timp, multe procese își pot efectua operațiunile și pot folosi procesorul fără a aștepta în timp ce imprimanta execută procesul de imprimare pe documente unul câte unul.

Multe caracteristici pot fi, de asemenea, adăugate procesului de imprimare Spooling, cum ar fi setarea priorităților sau notificarea când procesul de imprimare a fost finalizat sau selectarea diferitelor tipuri de hârtie pe care să se imprime în funcție de alegerea utilizatorului.
Avantajele Spooling-ului
Iată următoarele avantaje ale spoolării într-un sistem de operare, cum ar fi:
dormi pentru javascript
- Numărul de dispozitive I/O sau operațiuni nu contează. Multe dispozitive I/O pot lucra împreună simultan fără interferențe sau întreruperi unul cu celălalt.
- În spooling, nu există nicio interacțiune între dispozitivele I/O și CPU. Aceasta înseamnă că nu este nevoie ca CPU să aștepte ca operațiunile I/O să aibă loc. Executarea acestor operațiuni durează mult timp, astfel încât CPU nu va aștepta să se termine.
- CPU în starea inactivă nu este considerată foarte eficientă. Majoritatea protocoalelor sunt create pentru a utiliza eficient CPU-ul într-o perioadă minimă de timp. În spooling, CPU este ținut ocupat de cele mai multe ori și intră în starea inactivă doar când coada este epuizată. Deci, toate sarcinile sunt adăugate la coadă, iar CPU-ul va termina toate acele sarcini și apoi va intra în starea inactivă.
- Permite aplicațiilor să ruleze la viteza procesorului în timp ce operează dispozitivele I/O la viteze maxime respective.
Dezavantajele spooling-ului
Într-un sistem de operare, spooling-ul are următoarele dezavantaje, cum ar fi:
- Spooling-ul necesită o cantitate mare de stocare în funcție de numărul de solicitări făcute de intrare și de numărul de dispozitive de intrare conectate.
- Deoarece SPOOL este creat în spațiul de stocare secundar, faptul că mai multe dispozitive de intrare funcționează simultan poate ocupa mult spațiu pe stocarea secundară și, astfel, crește traficul pe disc. Astfel, discul devine din ce în ce mai lent pe măsură ce traficul crește din ce în ce mai mult.
- Spooling-ul este utilizat pentru copierea și executarea datelor de pe un dispozitiv mai lent pe un dispozitiv mai rapid. Dispozitivul mai lent creează un SPOOL pentru a stoca datele pentru a fi operate într-o coadă, iar CPU lucrează pe el. Acest proces în sine face ca Spoolingul să fie inutil de utilizat în medii în timp real în care avem nevoie de rezultate în timp real de la CPU. Acest lucru se datorează faptului că dispozitivul de intrare este mai lent și, astfel, își produce datele într-un ritm mai lent, în timp ce procesorul poate funcționa mai rapid, astfel încât trece la următorul proces din coadă. Acesta este motivul pentru care rezultatul sau rezultatul final este produs mai târziu, nu în timp real.
Diferența dintre spooling și buffering
Spooling și buffering sunt cele două moduri prin care subsistemele I/O îmbunătățesc performanța și eficiența computerului prin utilizarea unui spațiu de stocare în memoria principală sau pe disc.

Diferența de bază dintre spooling și buffering este că spooling se suprapune I/O unui job cu execuția altui job. În comparație, tamponarea suprapune I/E-ul unui job cu execuția aceluiași job. Mai jos sunt câteva diferențe suplimentare între Spooling și Buffering, cum ar fi:
| Termeni | Spooling | Buffering |
|---|---|---|
| Definiție | Spooling, acronim de la Simultaneous Peripheral Operation Online (SPOOL), plasează datele într-o zonă de lucru temporară pentru a fi accesate și procesate de un alt program sau resursă. | Buffering-ul este un act de stocare temporară a datelor în tampon. Ajută la potrivirea vitezei fluxului de date între emițător și receptor. |
| Nevoia de resurse | Spoolingul necesită mai puțină gestionare a resurselor, deoarece resurse diferite gestionează procesul pentru anumite sarcini. | Buffering-ul necesită mai mult management al resurselor, deoarece aceeași resursă gestionează procesul aceleiași sarcini divizate. |
| Implementare internă | Spoolingul suprapune intrarea și ieșirea unui job cu calculul altui job. | Buffering-ul suprapune intrarea și ieșirea unui job cu calculul aceluiași job. |
| Eficient | Spooling-ul este mai eficient decât tamponarea. | Buffering-ul este mai puțin eficient decât spooling. |
| Procesor | Spooling-ul poate procesa și date pe site-uri la distanță. Spooler-ul trebuie să notifice doar când un proces este finalizat la site-ul de la distanță pentru a distribui următorul proces către dispozitivul lateral de la distanță. | Buffering nu acceptă procesarea de la distanță. |
| Dimensiunea pe memorie | Consideră discul ca o bobină sau un buffer imens. | Bufferul este o zonă limitată din memoria principală. |