Ce este LRU Cache?
Algoritmii de înlocuire a memoriei cache sunt proiectați eficient pentru a înlocui memoria cache atunci când spațiul este plin. The Cel mai puțin recent folosit (LRU) este unul dintre acei algoritmi. După cum sugerează și numele când memoria cache este plină, LRU alege datele care au fost utilizate cel mai puțin recent și le elimină pentru a face spațiu pentru noile date. Prioritatea datelor din memoria cache se modifică în funcție de necesitatea acelor date, adică dacă unele date sunt preluate sau actualizate recent, atunci prioritatea acelor date va fi schimbată și atribuită celei mai mari priorități, iar prioritatea datelor scade dacă rămâne operațiuni neutilizate după operații.
Cuprins
- Ce este LRU Cache?
- Operațiuni pe cache LRU:
- Funcționarea LRU Cache:
- Modalități de implementare a LRU Cache:
- Implementarea cache-ului LRU folosind Queue și Hashing:
- Implementarea cache-ului LRU utilizând Listă dublu legată și Hashing:
- Implementarea cache-ului LRU folosind Deque & Hashmap:
- Implementarea cache-ului LRU folosind Stack & Hashmap:
- Cache-ul LRU folosind Implementarea Counter:
- Implementarea cache-ului LRU folosind Lazy Updates:
- Analiza complexității cache-ului LRU:
- Avantajele cache-ului LRU:
- Dezavantajele cache-ului LRU:
- Aplicația în lumea reală a LRU Cache:
LRU algoritmul este o problemă standard și poate avea variații în funcție de nevoi, de exemplu, în sistemele de operare LRU joacă un rol crucial, deoarece poate fi folosit ca algoritm de înlocuire a paginii pentru a minimiza erorile de pagină.
Operațiuni pe cache LRU:
- LRUCache (capacitate c): Inițializați memoria cache LRU cu capacitate de dimensiune pozitivă c.
- obține (cheia) : returnează valoarea cheii „ k’ dacă este prezent în cache, altfel returnează -1. De asemenea, actualizează prioritatea datelor din memoria cache LRU.
- pune (cheie, valoare): Actualizați valoarea cheii dacă acea cheie există. În caz contrar, adăugați perechea cheie-valoare în cache. Dacă numărul de chei a depășit capacitatea cache-ului LRU, atunci respingeți cheia folosită cel mai puțin recent.
Funcționarea LRU Cache:
Să presupunem că avem un cache LRU de capacitate 3 și am dori să efectuăm următoarele operații:
- Puneți (cheie=1, valoare=A) în cache
- Puneți (cheie=2, valoare=B) în cache
- Puneți (cheie=3, valoare=C) în cache
- Obțineți (cheie=2) din cache
- Obțineți (cheie=4) din cache
- Puneți (cheie=4, valoare=D) în cache
- Puneți (cheie=3, valoare=E) în cache
- Obțineți (cheie=4) din cache
- Puneți (cheie=1, valoare=A) în cache
Operațiile de mai sus sunt efectuate una după alta, așa cum se arată în imaginea de mai jos:
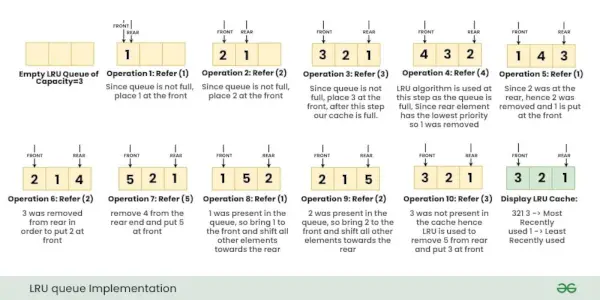
Explicație detaliată a fiecărei operațiuni:
- Put (cheia 1, valoarea A) : Deoarece memoria cache LRU are capacitate goală=3, nu este nevoie de nicio înlocuire și punem {1 : A} în partea de sus, adică {1 : A} are cea mai mare prioritate.
- Put (cheia 2, valoarea B) : Deoarece memoria cache LRU are capacitate goală = 2, din nou nu este nevoie de nicio înlocuire, dar acum {2 : B} are cea mai mare prioritate și prioritate de {1 : A} scade.
- Put (cheia 3, valoarea C) : Totuși există 1 spațiu liber liber în cache, așadar puneți {3 : C} fără nicio înlocuire, observați că acum cache-ul este plin și ordinea curentă de prioritate de la cea mai mare la cea mai mică este {3:C}, {2:B }, {1:A}.
- Obține (cheia 2) : Acum, returnați valoarea cheie=2 în timpul acestei operațiuni, de asemenea, deoarece este folosită cheia=2, acum noua ordine de prioritate este {2:B}, {3:C}, {1:A}
- Obțineți (cheia 4): Observați că cheia 4 nu este prezentă în cache, returnăm „-1” pentru această operație.
- Put (cheia 4, valoarea D) : Observați că memoria cache este FULL, acum utilizați algoritmul LRU pentru a determina care cheie a fost folosită cel mai puțin recent. Deoarece {1:A} a avut cea mai mică prioritate, eliminați {1:A} din memoria cache și puneți {4:D} în cache. Observați că noua ordine de prioritate este {4:D}, {2:B}, {3:C}
- Put (cheia 3, valoarea E) : Deoarece cheia=3 era deja prezentă în memoria cache având valoare=C, deci această operație nu va duce la eliminarea niciunei chei, mai degrabă va actualiza valoarea cheii=3 la „ ȘI' . Acum, noua ordine de prioritate va deveni {3:E}, {4:D}, {2:B}
- Obține (cheia 4) : Returnează valoarea key=4. Acum, noua prioritate va deveni {4:D}, {3:E}, {2:B}
- Put (cheia 1, valoarea A) : Deoarece memoria cache este PLINĂ, folosiți algoritmul nostru LRU pentru a determina ce cheie a fost folosită cel mai puțin recent și, deoarece {2:B} a avut cea mai mică prioritate, eliminați {2:B} din memoria cache și puneți {1:A} în cache. Acum, noua ordine de prioritate este {1:A}, {4:D}, {3:E}
Modalități de implementare a LRU Cache:
Cache-ul LRU poate fi implementat într-o varietate de moduri și fiecare programator poate alege o abordare diferită. Cu toate acestea, mai jos sunt abordările frecvent utilizate:
- LRU folosind Queue și Hashing
- LRU folosind Listă dublu legată + Hashing
- LRU folosind Deque
- LRU folosind Stack
- LRU folosind Implementarea contra
- LRU utilizând Lazy Updates
Implementarea cache-ului LRU folosind Queue și Hashing:
Folosim două structuri de date pentru a implementa un cache LRU.
- Coadă este implementat folosind o listă dublu legată. Dimensiunea maximă a cozii va fi egală cu numărul total de cadre disponibile (dimensiunea cache). Cele mai recente pagini utilizate vor fi aproape de partea din față, iar cele mai puțin recente pagini vor fi aproape de partea din spate.
- Un Hash cu numărul paginii ca cheie și adresa nodului corespunzător din coadă ca valoare.
Când se face referire la o pagină, pagina necesară poate fi în memorie. Dacă se află în memorie, trebuie să detașăm nodul listei și să-l aducem în fața cozii.
Dacă pagina necesară nu este în memorie, o aducem în memorie. Cu cuvinte simple, adăugăm un nou nod în fața cozii și actualizăm adresa nodului corespunzătoare în hash. Dacă coada este plină, adică toate cadrele sunt pline, eliminăm un nod din spatele cozii și adăugăm noul nod în partea din față a cozii.
Ilustrare:
Să luăm în considerare operațiunile, Se referă cheie X cu în memoria cache LRU: { 1, 2, 3, 4, 1, 2, 5, 1, 2, 3 }
Notă: Inițial nu există nicio pagină în memorie.Imaginile de mai jos arată execuția pas cu pas a operațiunilor de mai sus pe memoria cache LRU.
Algoritm:
- Creați o clasă LRUCache cu declara o listă de tip int, o hartă neordonată de tip
- În funcția de referință a LRUCache
- Dacă această valoare nu este prezentă în coadă, împingeți această valoare în fața cozii și eliminați ultima valoare dacă coada este plină
- Dacă valoarea este deja prezentă, eliminați-o din coadă și împingeți-o în fața cozii
- În funcția de afișare tipăriți, LRUCache-ul utilizând coada începând din față
Mai jos este implementarea abordării de mai sus:
C++
// We can use stl container list as a double> // ended queue to store the cache keys, with> // the descending time of reference from front> // to back and a set container to check presence> // of a key. But to fetch the address of the key> // in the list using find(), it takes O(N) time.> // This can be optimized by storing a reference> // (iterator) to each key in a hash map.> #include> using> namespace> std;> > class> LRUCache {> >// store keys of cache> >list<>int>>dq;>>> // store references of key in cache> >unordered_map<>int>, list<>int>>::iterator> ma;>>> csize;>// maximum capacity of cache> > public>:> >LRUCache(>int>);> >void> refer(>int>);> >void> display();> };> > // Declare the size> LRUCache::LRUCache(>int> n) { csize = n; }> > // Refers key x with in the LRU cache> void> LRUCache::refer(>int> x)> {> >// not present in cache> >if> (ma.find(x) == ma.end()) {> >// cache is full> >if> (dq.size() == csize) {> >// delete least recently used element> >int> last = dq.back();> > >// Pops the last element> >dq.pop_back();> > >// Erase the last> >ma.erase(last);> >}> >}> > >// present in cache> >else> >dq.erase(ma[x]);> > >// update reference> >dq.push_front(x);> >ma[x] = dq.begin();> }> > // Function to display contents of cache> void> LRUCache::display()> {> > >// Iterate in the deque and print> >// all the elements in it> >for> (>auto> it = dq.begin(); it != dq.end(); it++)> >cout << (*it) <<>' '>;> > >cout << endl;> }> > // Driver Code> int> main()> {> >LRUCache ca(4);> > >ca.refer(1);> >ca.refer(2);> >ca.refer(3);> >ca.refer(1);> >ca.refer(4);> >ca.refer(5);> >ca.display();> > >return> 0;> }> // This code is contributed by Satish Srinivas> |
>
>
arraylist
C
// A C program to show implementation of LRU cache> #include> #include> > // A Queue Node (Queue is implemented using Doubly Linked> // List)> typedef> struct> QNode {> >struct> QNode *prev, *next;> >unsigned> >pageNumber;>// the page number stored in this QNode> } QNode;> > // A Queue (A FIFO collection of Queue Nodes)> typedef> struct> Queue {> >unsigned count;>// Number of filled frames> >unsigned numberOfFrames;>// total number of frames> >QNode *front, *rear;> } Queue;> > // A hash (Collection of pointers to Queue Nodes)> typedef> struct> Hash {> >int> capacity;>// how many pages can be there> >QNode** array;>// an array of queue nodes> } Hash;> > // A utility function to create a new Queue Node. The queue> // Node will store the given 'pageNumber'> QNode* newQNode(unsigned pageNumber)> {> >// Allocate memory and assign 'pageNumber'> >QNode* temp = (QNode*)>malloc>(>sizeof>(QNode));> >temp->pageNumber = pageNumber;>>> // Initialize prev and next as NULL> >temp->prev = temp->next = NULL;>>> return> temp;> }> > // A utility function to create an empty Queue.> // The queue can have at most 'numberOfFrames' nodes> Queue* createQueue(>int> numberOfFrames)> {> >Queue* queue = (Queue*)>malloc>(>sizeof>(Queue));> > >// The queue is empty> >queue->număr = 0;>>> // Number of frames that can be stored in memory> >queue->numberOfFrames = numberOfFrames;>>> return> queue;> }> > // A utility function to create an empty Hash of given> // capacity> Hash* createHash(>int> capacity)> {> >// Allocate memory for hash> >Hash* hash = (Hash*)>malloc>(>sizeof>(Hash));> >hash->capacitate = capacitate;>>> // Create an array of pointers for referring queue nodes> >hash->matrice>>> malloc>(hash->capacitate *>>> > >// Initialize all hash entries as empty> >int> i;> >for> (i = 0; i capacity; ++i)> >hash->matrice[i] = NULL;>>> return> hash;> }> > // A function to check if there is slot available in memory> int> AreAllFramesFull(Queue* queue)> {> >return> queue->count == coada->numarOfFrames;>>> // A utility function to check if queue is empty> int> isQueueEmpty(Queue* queue)> {> >return> queue->spate == NULL;>>> // A utility function to delete a frame from queue> void> deQueue(Queue* queue)> {> >if> (isQueueEmpty(queue))> >return>;> > >// If this is the only node in list, then change front> >if> (queue->fata == coada->spate)>> >queue->fata = NULL;>>> // Change rear and remove the previous rear> >QNode* temp = queue->spate;>>> if> (queue->spate)>>> free>(temp);> > >// decrement the number of full frames by 1> >queue->numara--;>>> // A function to add a page with given 'pageNumber' to both> // queue and hash> void> Enqueue(Queue* queue, Hash* hash, unsigned pageNumber)> {> >// If all frames are full, remove the page at the rear> >if> (AreAllFramesFull(queue)) {> >// remove page from hash> >hash->matrice[coadă->spate->număr pagină] = NULL;>>> >}> > >// Create a new node with given page number,> >// And add the new node to the front of queue> >QNode* temp = newQNode(pageNumber);> >temp->următor = coadă->față;>>> // If queue is empty, change both front and rear> >// pointers> >if> (isQueueEmpty(queue))> >queue->spate = coada->fata = temp;>>> // Else change the front> >{> >queue->front->prev = temp;>>> > >// Add page entry to hash also> >hash->matrice[pageNumber] = temp;>>> // increment number of full frames> >queue->numără++;>>> // This function is called when a page with given> // 'pageNumber' is referenced from cache (or memory). There> // are two cases:> // 1. Frame is not there in memory, we bring it in memory> // and add to the front of queue> // 2. Frame is there in memory, we move the frame to front> // of queue> void> ReferencePage(Queue* queue, Hash* hash,> >unsigned pageNumber)> {> >QNode* reqPage = hash->matrice[pageNumber];>>> // the page is not in cache, bring it> >if> (reqPage == NULL)> >Enqueue(queue, hash, pageNumber);> > >// page is there and not at front, change pointer> >else> if> (reqPage != queue->fata) {>>> >// in queue.> >reqPage->prev->next = reqPage->next;>>> (reqPage->următorul)>>> // If the requested page is rear, then change rear> >// as this node will be moved to front> >if> (reqPage == queue->spate) {>>> > >// Put the requested page before current front> >reqPage->următor = coadă->față;>>> // Change prev of current front> >reqPage->următor->prev = reqPage;>>> // Change front to the requested page> >queue->front = reqPage;>>> }> > // Driver code> int> main()> {> >// Let cache can hold 4 pages> >Queue* q = createQueue(4);> > >// Let 10 different pages can be requested (pages to be> >// referenced are numbered from 0 to 9> >Hash* hash = createHash(10);> > >// Let us refer pages 1, 2, 3, 1, 4, 5> >ReferencePage(q, hash, 1);> >ReferencePage(q, hash, 2);> >ReferencePage(q, hash, 3);> >ReferencePage(q, hash, 1);> >ReferencePage(q, hash, 4);> >ReferencePage(q, hash, 5);> > >// Let us print cache frames after the above referenced> >// pages> >printf>(>'%d '>, q->front->pageNumber);>>> (>'%d '>, q->front->next->pageNumber);>>> (>'%d '>, q->front->next->next->pageNumber);>>> (>'%d '>, q->front->next->next->next->pageNumber);>>> return> 0;> }> |
>
>
cum se rulează un script în linux
Java
/* We can use Java inbuilt Deque as a double> >ended queue to store the cache keys, with> >the descending time of reference from front> >to back and a set container to check presence> >of a key. But remove a key from the Deque using> >remove(), it takes O(N) time. This can be> >optimized by storing a reference (iterator) to> >each key in a hash map. */> import> java.util.Deque;> import> java.util.HashSet;> import> java.util.Iterator;> import> java.util.LinkedList;> > public> class> LRUCache {> > >// store keys of cache> >private> Deque doublyQueue;> > >// store references of key in cache> >private> HashSet hashSet;> > >// maximum capacity of cache> >private> final> int> CACHE_SIZE;> > >LRUCache(>int> capacity)> >{> >doublyQueue =>new> LinkedList();> >hashSet =>new> HashSet();> >CACHE_SIZE = capacity;> >}> > >/* Refer the page within the LRU cache */> >public> void> refer(>int> page)> >{> >if> (!hashSet.contains(page)) {> >if> (doublyQueue.size() == CACHE_SIZE) {> >int> last = doublyQueue.removeLast();> >hashSet.remove(last);> >}> >}> >else> {>/* The found page may not be always the last> >element, even if it's an intermediate> >element that needs to be removed and added> >to the start of the Queue */> >doublyQueue.remove(page);> >}> >doublyQueue.push(page);> >hashSet.add(page);> >}> > >// display contents of cache> >public> void> display()> >{> >Iterator itr = doublyQueue.iterator();> >while> (itr.hasNext()) {> >System.out.print(itr.next() +>' '>);> >}> >}> > >// Driver code> >public> static> void> main(String[] args)> >{> >LRUCache cache =>new> LRUCache(>4>);> >cache.refer(>1>);> >cache.refer(>2>);> >cache.refer(>3>);> >cache.refer(>1>);> >cache.refer(>4>);> >cache.refer(>5>);> >cache.display();> >}> }> // This code is contributed by Niraj Kumar> |
>
>
Python3
# We can use stl container list as a double> # ended queue to store the cache keys, with> # the descending time of reference from front> # to back and a set container to check presence> # of a key. But to fetch the address of the key> # in the list using find(), it takes O(N) time.> # This can be optimized by storing a reference> # (iterator) to each key in a hash map.> class> LRUCache:> ># store keys of cache> >def> __init__(>self>, n):> >self>.csize>=> n> >self>.dq>=> []> >self>.ma>=> {}> > > ># Refers key x with in the LRU cache> >def> refer(>self>, x):> > ># not present in cache> >if> x>not> in> self>.ma.keys():> ># cache is full> >if> len>(>self>.dq)>=>=> self>.csize:> ># delete least recently used element> >last>=> self>.dq[>->1>]> > ># Pops the last element> >ele>=> self>.dq.pop();> > ># Erase the last> >del> self>.ma[last]> > ># present in cache> >else>:> >del> self>.dq[>self>.ma[x]]> > ># update reference> >self>.dq.insert(>0>, x)> >self>.ma[x]>=> 0>;> > ># Function to display contents of cache> >def> display(>self>):> > ># Iterate in the deque and print> ># all the elements in it> >print>(>self>.dq)> > # Driver Code> ca>=> LRUCache(>4>)> > ca.refer(>1>)> ca.refer(>2>)> ca.refer(>3>)> ca.refer(>1>)> ca.refer(>4>)> ca.refer(>5>)> ca.display()> # This code is contributed by Satish Srinivas> |
>
>
C#
// C# program to implement the approach> > using> System;> using> System.Collections.Generic;> > class> LRUCache {> >// store keys of cache> >private> List<>int>>doublelyQueue;>>> // store references of key in cache> >private> HashSet<>int>>hashSet;>>> // maximum capacity of cache> >private> int> CACHE_SIZE;> > >public> LRUCache(>int> capacity)> >{> >doublyQueue =>new> List<>int>>();>>> new> HashSet<>int>>();>>> >}> > >/* Refer the page within the LRU cache */> >public> void> Refer(>int> page)> >{> >if> (!hashSet.Contains(page)) {> >if> (doublyQueue.Count == CACHE_SIZE) {> >int> last> >= doublyQueue[doublyQueue.Count - 1];> >doublyQueue.RemoveAt(doublyQueue.Count - 1);> >hashSet.Remove(last);> >}> >}> >else> {> >/* The found page may not be always the last> >element, even if it's an intermediate> >element that needs to be removed and added> >to the start of the Queue */> >doublyQueue.Remove(page);> >}> >doublyQueue.Insert(0, page);> >hashSet.Add(page);> >}> > >// display contents of cache> >public> void> Display()> >{> >foreach>(>int> page>in> doublyQueue)> >{> >Console.Write(page +>' '>);> >}> >}> > >// Driver code> >static> void> Main(>string>[] args)> >{> >LRUCache cache =>new> LRUCache(4);> >cache.Refer(1);> >cache.Refer(2);> >cache.Refer(3);> >cache.Refer(1);> >cache.Refer(4);> >cache.Refer(5);> >cache.Display();> >}> }> > // This code is contributed by phasing17> |
>
>
Javascript
// JS code to implement the approach> class LRUCache {> >constructor(n) {> >this>.csize = n;> >this>.dq = [];> >this>.ma =>new> Map();> >}> > >refer(x) {> >if> (!>this>.ma.has(x)) {> >if> (>this>.dq.length ===>this>.csize) {> >const last =>this>.dq[>this>.dq.length - 1];> >this>.dq.pop();> >this>.ma.>delete>(last);> >}> >}>else> {> >this>.dq.splice(>this>.dq.indexOf(x), 1);> >}> > >this>.dq.unshift(x);> >this>.ma.set(x, 0);> >}> > >display() {> >console.log(>this>.dq);> >}> }> > const cache =>new> LRUCache(4);> > cache.refer(1);> cache.refer(2);> cache.refer(3);> cache.refer(1);> cache.refer(4);> cache.refer(5);> cache.display();> > // This code is contributed by phasing17> |
>
emoji-uri iPhone pe telefonul Android
>
Implementarea cache-ului LRU utilizând Listă dublu legată și Hashing :
Ideea este foarte de bază, adică continuă să introduci elementele la cap.
- dacă elementul nu este prezent în listă, adăugați-l în capul listei
- dacă elementul este prezent în listă, atunci mutați elementul în cap și mutați elementul rămas din listă
Rețineți că prioritatea nodului va depinde de distanța acelui nod față de cap, cu cât nodul este cel mai aproape de cap, cu atât este mai mare prioritatea pe care o are. Deci, atunci când dimensiunea cache este plină și trebuie să eliminăm un element, eliminăm elementul adiacent la coada listei dublu legate.
Implementarea cache-ului LRU folosind Deque & Hashmap:
Structura de date Deque permite inserarea și ștergerea atât din față, cât și de la capăt, această proprietate permite implementarea LRU posibilă, deoarece elementul Front poate reprezenta element cu prioritate ridicată, în timp ce elementul final poate fi elementul cu prioritate scăzută, adică cel mai puțin recent utilizat.
Lucru:
- Obține operație : Verifică dacă cheia există în harta hash a cache-ului și urmează cazurile de mai jos pe deque:
- Dacă se găsește cheia:
- Elementul este considerat ca fiind folosit recent, așa că este mutat în partea din față a decului.
- Valoarea asociată cheii este returnată ca rezultat al
get>Operațiune.- Dacă cheia nu este găsită:
- returnați -1 pentru a indica că nu există o astfel de cheie.
- Operațiunea Pune: Mai întâi verificați dacă cheia există deja în harta hash a cache-ului și urmați cazurile de mai jos pe deque
- Dacă există cheia:
- Valoarea asociată cheii este actualizată.
- Elementul este mutat în partea din față a decului, deoarece acum este cel mai recent folosit.
- Dacă cheia nu există:
- Dacă memoria cache este plină, înseamnă că trebuie introdus un nou articol, iar elementul cel mai puțin recent folosit trebuie evacuat. Acest lucru se face prin eliminarea articolului de la sfârșitul deque-ului și a intrării corespunzătoare din harta hash.
- Noua pereche cheie-valoare este apoi inserată atât în harta hash, cât și în partea din față a deque-ului pentru a semnifica că este cel mai recent element utilizat
Implementarea cache-ului LRU folosind Stack & Hashmap:
Implementarea unui cache LRU (Cel mai puțin folosit recent) folosind o structură de date stivă și hashing poate fi puțin dificilă, deoarece o stivă simplă nu oferă acces eficient la elementul cel mai puțin recent utilizat. Cu toate acestea, puteți combina o stivă cu o hartă hash pentru a realiza acest lucru eficient. Iată o abordare la nivel înalt pentru a o implementa:
- Utilizați o hartă Hash : Harta hash va stoca perechile cheie-valoare ale memoriei cache. Cheile se vor mapa la nodurile corespunzătoare din stivă.
- Utilizați o stivă : Stiva va menține ordinea cheilor în funcție de utilizarea lor. Cel mai puțin recent articol folosit va fi în partea de jos a stivei, iar cel mai recent element folosit va fi în partea de sus
Această abordare nu este atât de eficientă și, prin urmare, nu este folosită des.
Cache-ul LRU utilizând implementarea Counter:
Fiecare bloc din cache va avea propriul său contor LRU, căruia îi aparține valoarea contorului {0 la n-1} , Aici ' n ‘ reprezintă dimensiunea memoriei cache. Blocul care este schimbat în timpul înlocuirii blocului devine blocul MRU și, ca urmare, valoarea sa de contor este schimbată la n – 1. Valorile contorului mai mari decât valoarea contorului blocului accesat sunt decrementate cu unu. Blocurile rămase sunt nemodificate.
| Valoarea lui Conter | Prioritate | Stare folosită |
|---|---|---|
| 0 | Scăzut | Cel mai puțin recent folosit |
| n-1 | Înalt | Cel mai recent folosit |
Implementarea cache-ului LRU folosind Lazy Updates:
Implementarea unui cache LRU (Cel mai puțin folosit recent) folosind actualizări lenețe este o tehnică comună pentru a îmbunătăți eficiența operațiunilor cache-ului. Actualizările lazy implică urmărirea ordinii în care articolele sunt accesate fără a actualiza imediat întreaga structură de date. Când apare o pierdere a memoriei cache, puteți decide dacă efectuați sau nu o actualizare completă pe baza unor criterii.
Analiza complexității cache-ului LRU:
- Complexitatea timpului:
- Operațiunea Put(): O(1), adică timpul necesar pentru a introduce sau actualiza noua pereche cheie-valoare este constant
- Operația Get(): O(1), adică timpul necesar pentru a obține valoarea unei chei este constant
- Spațiu auxiliar: O(N) unde N este capacitatea cache-ului.
Avantajele cache-ului LRU:
- Acces rapid : Este nevoie de timp O(1) pentru a accesa datele din memoria cache LRU.
- Actualizare rapidă : Este nevoie de timp O(1) pentru a actualiza o pereche cheie-valoare din memoria cache LRU.
- Eliminarea rapidă a datelor cel mai puțin utilizate recent : Este nevoie de O(1) șterge ceea ce nu a fost folosit recent.
- Fără batere: LRU este mai puțin susceptibil la thrashing în comparație cu FIFO, deoarece ia în considerare istoricul utilizării paginilor. Poate detecta ce pagini sunt utilizate frecvent și le poate acorda prioritate pentru alocarea memoriei, reducând numărul de erori de pagină și operațiuni de I/O pe disc.
Dezavantajele cache-ului LRU:
- Este nevoie de o dimensiune mare a memoriei cache pentru a crește eficiența.
- Este necesară implementarea unei structuri de date suplimentare.
- Asistența hardware este mare.
- În LRU, detectarea erorilor este dificilă în comparație cu alți algoritmi.
- Are o acceptabilitate limitată.
Aplicația în lumea reală a LRU Cache:
- În sistemele de baze de date pentru rezultate rapide de interogare.
- În sistemele de operare pentru a minimiza erorile de pagină.
- Editore de text și IDE-uri pentru a stoca fișiere utilizate frecvent sau fragmente de cod
- Routerele și comutatoarele de rețea folosesc LRU pentru a crește eficiența rețelei de calculatoare
- În optimizările compilatorului
- Instrumente de predicție a textului și completare automată