În lumea reală, nu toate datele la care lucrăm au o variabilă țintă. Acest tip de date nu pot fi analizate folosind algoritmi de învățare supravegheată. Avem nevoie de ajutorul unor algoritmi nesupravegheați. Unul dintre cele mai populare tipuri de analiză sub învățarea nesupravegheată este segmentarea clienților pentru reclame vizate sau în imagistica medicală pentru a găsi zone infectate necunoscute sau noi și multe alte cazuri de utilizare pe care le vom discuta în continuare în acest articol.
Cuprins
- Ce este Clustering?
- Tipuri de clustering
- Utilizări ale grupării
- Tipuri de algoritmi de clusterizare
- Aplicații ale Clusteringului în diferite domenii:
- Întrebări frecvente (FAQs) despre clustering
Ce este Clustering?
Sarcina de grupare a punctelor de date pe baza asemănării lor între ele se numește Clustering sau Cluster Analysis. Această metodă este definită sub ramura a Învățare nesupravegheată , care are ca scop obținerea de informații din puncte de date neetichetate, adică spre deosebire de învăţare supravegheată nu avem o variabilă țintă.
Clustering-ul urmărește formarea de grupuri de puncte de date omogene dintr-un set de date eterogen. Evaluează asemănarea pe baza unei metrici precum distanța euclidiană, asemănarea cosinusului, distanța Manhattan etc. și apoi grupează punctele cu cel mai mare scor de asemănare.
De exemplu, în graficul de mai jos, putem vedea clar că există 3 grupuri circulare care se formează pe baza distanței.
structura java
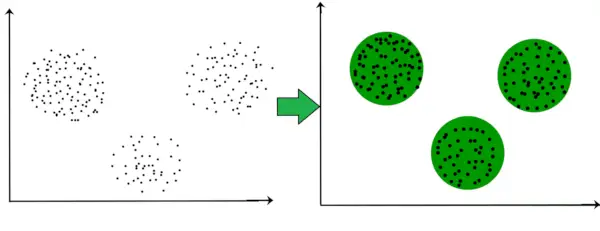
Acum nu este necesar ca ciorchinii formați să aibă formă circulară. Forma clusterelor poate fi arbitrară. Există mulți algoritmi care funcționează bine cu detectarea clusterelor de formă arbitrară.
logica de ordinul întâi
De exemplu, în graficul de mai jos putem vedea că grupurile formate nu au formă circulară.

Tipuri de clustering
În linii mari, există două tipuri de grupare care pot fi efectuate pentru a grupa puncte de date similare:
- Hard Clustering: În acest tip de clustering, fiecare punct de date aparține unui cluster complet sau nu. De exemplu, să presupunem că există 4 puncte de date și trebuie să le grupăm în 2 clustere. Deci fiecare punct de date va aparține fie clusterului 1, fie clusterului 2.
| Puncte de date | Clustere |
|---|---|
| A | C1 |
| B | C2 |
| C | C2 |
| D | C1 |
- Clustering soft: În acest tip de grupare, în loc să aloce fiecare punct de date într-un cluster separat, se evaluează probabilitatea sau probabilitatea ca acel punct să fie acel cluster. De exemplu, să presupunem că există 4 puncte de date și trebuie să le grupăm în 2 clustere. Deci vom evalua probabilitatea ca un punct de date să aparțină ambelor grupuri. Această probabilitate este calculată pentru toate punctele de date.
| Puncte de date | Probabilitatea de C1 | Probabilitatea de C2 |
| A | 0,91 | 0,09 |
| B | 0,3 | 0,7 |
| C | 0,17 | 0,83 |
| D | 1 | 0 |
Utilizări ale grupării
Acum, înainte de a începe cu tipurile de algoritmi de clustering, vom trece prin cazurile de utilizare ale algoritmilor de clustering. Algoritmii de grupare sunt utilizați în principal pentru:
- Segmentarea pieței – Companiile folosesc gruparea pentru a-și grupa clienții și folosesc reclame direcționate pentru a atrage mai multă audiență.
- Analiza rețelelor sociale – Site-urile de socializare vă folosesc datele pentru a vă înțelege comportamentul de navigare și pentru a vă oferi recomandări de prieteni sau recomandări de conținut.
- Imagistica medicală – Medicii folosesc Clustering pentru a descoperi zonele bolnave din imaginile de diagnostic, cum ar fi razele X.
- Detectarea anomaliilor – Pentru a găsi valori aberante într-un flux de date în timp real sau pentru a estima tranzacții frauduloase, putem folosi gruparea pentru a le identifica.
- Simplificați lucrul cu seturi de date mari – Fiecărui cluster i se atribuie un ID de cluster după ce gruparea este finalizată. Acum, puteți reduce întregul set de caracteristici al unui set de caracteristici în ID-ul său de cluster. Clustering-ul este eficient atunci când poate reprezenta un caz complicat cu un ID de cluster simplu. Folosind același principiu, gruparea datelor poate simplifica seturile de date complexe.
Există multe mai multe cazuri de utilizare pentru clustering, dar există unele dintre cazurile de utilizare majore și comune ale grupării. În continuare, vom discuta despre algoritmii de grupare care vă vor ajuta să îndepliniți sarcinile de mai sus.
Tipuri de algoritmi de clusterizare
La nivel de suprafață, gruparea ajută la analiza datelor nestructurate. Graficul, distanța cea mai scurtă și densitatea punctelor de date sunt câteva dintre elementele care influențează formarea clusterelor. Clustering este procesul de determinare a modului în care obiectele sunt legate pe baza unei metrici numită măsură de similaritate. Valorile de similaritate sunt mai ușor de găsit în seturi mai mici de caracteristici. Devine mai greu să creezi măsuri de similaritate pe măsură ce crește numărul de caracteristici. În funcție de tipul de algoritm de clustering utilizat în data mining, sunt folosite mai multe tehnici pentru a grupa datele din seturile de date. În această parte sunt descrise tehnicile de grupare. Diferite tipuri de algoritmi de grupare sunt:
Comandă rapidă cu majuscule excel
- Clustering bazat pe centroid (metode de partiționare)
- Clustering bazat pe densitate (metode bazate pe model)
- Clustering bazat pe conectivitate (clustering ierarhic)
- Clustering bazat pe distribuție
Vom analiza pe scurt fiecare dintre aceste tipuri.
1. Metodele de partiționare sunt cei mai simpli algoritmi de grupare. Ei grupează punctele de date în funcție de apropierea lor. În general, măsura de similitudine aleasă pentru acești algoritmi sunt distanța euclidiană, distanța Manhattan sau distanța Minkowski. Seturile de date sunt separate într-un număr predeterminat de clustere, iar fiecare cluster este referit printr-un vector de valori. În comparație cu valoarea vectorială, variabila de date de intrare nu prezintă nicio diferență și se alătură clusterului.
Principalul dezavantaj al acestor algoritmi este cerința de a stabili numărul de clustere, k, fie intuitiv, fie științific (folosind metoda Elbow) înainte ca orice sistem de învățare automată de clustering să înceapă să aloce punctele de date. În ciuda acestui fapt, este încă cel mai popular tip de grupare. K-înseamnă și K-medoide clustering sunt câteva exemple de acest tip de clustering.
int la șir de caractere java
2. Clustering bazat pe densitate (metode bazate pe model)
Gruparea bazată pe densitate, o metodă bazată pe model, găsește grupuri pe baza densității punctelor de date. Spre deosebire de gruparea bazată pe centroid, care necesită ca numărul de clustere să fie predefinit și este sensibil la inițializare, gruparea bazată pe densitate determină automat numărul de clustere și este mai puțin susceptibilă la pozițiile de început. Sunt excelente la manipularea clusterelor de diferite dimensiuni și forme, ceea ce le face ideal pentru seturi de date cu clustere de formă neregulată sau care se suprapun. Aceste metode gestionează atât regiunile de date dense, cât și cele rare, concentrându-se pe densitatea locală și pot distinge clustere cu o varietate de morfologii.
În schimb, gruparea bazată pe centroid, ca și k-means, are probleme în găsirea clusterelor de formă arbitrară. Datorită numărului său prestabilit de cerințe de cluster și sensibilității extreme la poziționarea inițială a centroizilor, rezultatele pot varia. În plus, tendința abordărilor bazate pe centroizi de a produce clustere sferice sau convexe le restrânge capacitatea de a gestiona clustere complicate sau de formă neregulată. În concluzie, gruparea bazată pe densitate depășește dezavantajele tehnicilor bazate pe centroid prin alegerea autonomă a dimensiunilor clusterelor, fiind rezistentă la inițializare și captarea cu succes a clusterelor de diferite dimensiuni și forme. Cel mai popular algoritm de grupare bazat pe densitate este DBSCAN .
3. Clustering bazat pe conectivitate (clustering ierarhic)
O metodă de asamblare a punctelor de date înrudite în clustere ierarhice se numește clustering ierarhic. Fiecare punct de date este inițial luat în considerare ca un cluster separat, care este ulterior combinat cu clusterele care sunt cele mai asemănătoare pentru a forma un cluster mare care conține toate punctele de date.
Gândiți-vă cum puteți aranja o colecție de articole în funcție de cât de asemănătoare sunt. Fiecare obiect începe ca propriul său cluster la baza arborelui atunci când se utilizează gruparea ierarhică, care creează o dendrogramă, o structură asemănătoare arborelui. Cele mai apropiate perechi de clustere sunt apoi combinate în clustere mai mari după ce algoritmul examinează cât de asemănătoare sunt obiectele între ele. Când fiecare obiect se află într-un grup în partea de sus a arborelui, procesul de îmbinare s-a încheiat. Explorarea diferitelor niveluri de granularitate este unul dintre lucrurile distractive ale grupării ierarhice. Pentru a obține un anumit număr de clustere, puteți selecta să tăiați dendrograma la o anumită înălțime. Cu cât două obiecte sunt mai asemănătoare într-un grup, cu atât sunt mai aproape. Este comparabil cu clasificarea articolelor în funcție de arborele lor genealogic, unde rudele cele mai apropiate sunt grupate împreună, iar ramurile mai largi semnifică conexiuni mai generale. Există două abordări pentru gruparea ierarhică:
- Clustering divizor : Urmează o abordare de sus în jos, aici considerăm că toate punctele de date fac parte dintr-un cluster mare și apoi acest cluster este împărțit în grupuri mai mici.
- Clustering aglomerativ : Urmează o abordare de jos în sus, aici considerăm că toate punctele de date fac parte din clustere individuale și apoi aceste clustere sunt combinate pentru a forma un cluster mare cu toate punctele de date.
4. Clustering bazat pe distribuție
Folosind gruparea bazată pe distribuție, punctele de date sunt generate și organizate în funcție de tendința lor de a se încadra în aceeași distribuție de probabilitate (cum ar fi un gaussian, un binom sau altul) în cadrul datelor. Elementele de date sunt grupate folosind o distribuție bazată pe probabilitate care se bazează pe distribuții statistice. Sunt incluse obiectele de date care au o probabilitate mai mare de a fi în cluster. Este mai puțin probabil ca un punct de date să fie inclus într-un cluster cu cât este mai departe de punctul central al clusterului, care există în fiecare cluster.
Un dezavantaj notabil al abordărilor bazate pe densitate și limite este necesitatea de a specifica clusterele a priori pentru unii algoritmi și, în primul rând, definirea formei clusterului pentru cea mai mare parte a algoritmilor. Trebuie să existe cel puțin un reglaj sau un hiper-parametru selectat și, în timp ce procedați astfel, ar trebui să fie simplu, greșirea ar putea avea repercusiuni neprevăzute. Gruparea bazată pe distribuție are un avantaj clar față de abordările de clusterizare bazate pe proximitate și centroid în ceea ce privește flexibilitatea, acuratețea și structura clusterului. Problema cheie este că, pentru a evita supraadaptare , multe metode de grupare funcționează numai cu date simulate sau fabricate sau atunci când cea mai mare parte a punctelor de date aparțin cu siguranță unei distribuții prestabilite. Cel mai popular algoritm de clusterizare bazat pe distribuție este Modelul de amestec gaussian .
Aplicații ale Clusteringului în diferite domenii:
- Marketing: Poate fi folosit pentru a caracteriza și descoperi segmente de clienți în scopuri de marketing.
- Biologie: Poate fi folosit pentru clasificare între diferite specii de plante și animale.
- Biblioteci: Este folosit în gruparea diferitelor cărți pe baza subiectelor și informațiilor.
- Asigurare: Este folosit pentru a recunoaște clienții, politicile acestora și pentru a identifica fraudele.
- Urbanism: Este folosit pentru a face grupuri de case și pentru a le studia valorile pe baza locațiilor lor geografice și a altor factori prezenți.
- Studii de cutremur: Învățând zonele afectate de cutremur putem determina zonele periculoase.
- Procesarea imaginii : Clustering poate fi utilizat pentru a grupa imagini similare împreună, pentru a clasifica imaginile în funcție de conținut și pentru a identifica modele în datele de imagine.
- Genetica: Clustering este utilizat pentru a grupa gene care au modele de expresie similare și pentru a identifica rețele de gene care lucrează împreună în procesele biologice.
- Finanţa: Clusteringul este utilizat pentru a identifica segmente de piață pe baza comportamentului clienților, pentru a identifica modele în datele pieței bursiere și pentru a analiza riscul în portofoliile de investiții.
- Serviciu clienți: Gruparea este utilizată pentru a grupa întrebările și reclamațiile clienților în categorii, pentru a identifica problemele comune și pentru a dezvolta soluții țintite.
- de fabricație : Clustering este folosit pentru a grupa produse similare, pentru a optimiza procesele de producție și pentru a identifica defectele proceselor de fabricație.
- Diagnostic medical: Gruparea este utilizată pentru a grupa pacienții cu simptome sau boli similare, ceea ce ajută la stabilirea diagnosticelor precise și la identificarea tratamentelor eficiente.
- Detectarea fraudei: Clusteringul este utilizat pentru a identifica modele suspecte sau anomalii în tranzacțiile financiare, care pot ajuta la detectarea fraudelor sau a altor infracțiuni financiare.
- Analiza traficului: Gruparea este utilizată pentru a grupa modele similare de date de trafic, cum ar fi orele de vârf, rutele și vitezele, care pot ajuta la îmbunătățirea planificării și a infrastructurii de transport.
- Analiza rețelelor sociale: Clusteringul este folosit pentru a identifica comunități sau grupuri din cadrul rețelelor sociale, ceea ce poate ajuta la înțelegerea comportamentului social, influenței și tendințelor.
- Securitate cibernetică: Clustering-ul este utilizat pentru a grupa modele similare de trafic de rețea sau de comportament al sistemului, care pot ajuta la detectarea și prevenirea atacurilor cibernetice.
- Analiza climatică: Clustering este utilizat pentru a grupa modele similare de date climatice, cum ar fi temperatura, precipitațiile și vântul, care pot ajuta la înțelegerea schimbărilor climatice și a impactului acestora asupra mediului.
- Analiza sportului: Clustering este folosit pentru a grupa modele similare de date despre performanța jucătorilor sau a echipei, ceea ce poate ajuta la analiza punctelor forte și a punctelor slabe ale jucătorilor sau echipei și la luarea deciziilor strategice.
- Analiza criminalității: Gruparea este utilizată pentru a grupa modele similare de date despre criminalitate, cum ar fi locația, ora și tipul, care pot ajuta la identificarea punctelor fierbinți de criminalitate, la prezicerea tendințelor viitoare ale criminalității și la îmbunătățirea strategiilor de prevenire a criminalității.
Concluzie
În acest articol am discutat despre clustering, despre tipurile sale și despre aplicațiile sale în lumea reală. Există mult mai multe de acoperit în învățarea nesupravegheată, iar analiza grupurilor este doar primul pas. Acest articol vă poate ajuta să începeți cu algoritmii de Clustering și vă poate ajuta să obțineți un nou proiect care poate fi adăugat portofoliului dvs.
Întrebări frecvente (FAQs) despre clustering
Î. Care este cea mai bună metodă de grupare?
Primii 10 algoritmi de grupare sunt:
numerotati alfabetul
- K înseamnă Clustering
- Clustering ierarhic
- DBSCAN (Clustering spațial bazat pe densitate a aplicațiilor cu zgomot)
- Modele de amestec gaussiene (GMM)
- Clustering aglomerativ
- Clustering spectral
- Mean Shift Clustering
- Propagarea afinității
- OPTICĂ (Puncte de comandă pentru a identifica structura de grupare)
- Birch (reducere iterativă echilibrată și grupare folosind ierarhii)
Î. Care este diferența dintre grupare și clasificare?
Principala diferență dintre grupare și clasificare este că, clasificarea este un algoritm de învățare supravegheată, iar gruparea este un algoritm de învățare nesupravegheată. Adică, aplicăm gruparea acelor seturi de date care nu au o variabilă țintă.
Î. Care sunt avantajele analizei grupării?
Datele pot fi organizate în grupuri semnificative folosind instrumentul analitic puternic al analizei cluster. Îl puteți folosi pentru a identifica segmente, pentru a găsi modele ascunse și pentru a îmbunătăți deciziile.
Î. Care este cea mai rapidă metodă de grupare?
Gruparea K-means este adesea considerată cea mai rapidă metodă de grupare datorită simplității și eficienței sale de calcul. Atribuie iterativ puncte de date celui mai apropiat centroid al clusterului, făcându-l potrivit pentru seturi mari de date cu dimensionalitate scăzută și un număr moderat de clustere.
Î. Care sunt limitările grupării?
Limitările grupării includ sensibilitatea la condițiile inițiale, dependența de alegerea parametrilor, dificultatea de a determina numărul optim de clustere și provocările legate de manipularea datelor cu dimensiuni mari sau zgomotoase.
Î. De ce depinde calitatea rezultatului grupării?
Calitatea rezultatelor grupării depinde de factori precum alegerea algoritmului, metrica distanței, numărul de clustere, metoda de inițializare, tehnicile de preprocesare a datelor, metricile de evaluare a clusterului și cunoștințele domeniului. Aceste elemente influențează colectiv eficacitatea și acuratețea rezultatului grupării.