Un aspect important al Învățare automată este evaluarea modelului. Trebuie să aveți un mecanism pentru a vă evalua modelul. Aici intră în imagine aceste valori de performanță, care ne oferă o idee despre cât de bun este un model. Dacă sunteți familiarizat cu unele dintre elementele de bază ale Învățare automată atunci trebuie să fi întâlnit unele dintre aceste metrici, cum ar fi acuratețea, precizia, rechemarea, auc-roc etc., care sunt utilizate în general pentru sarcini de clasificare. În acest articol, vom explora în profunzime o astfel de metrică, care este curba AUC-ROC.
Cuprins
converti șirul în int
- Ce este curba AUC-ROC?
- Termeni cheie utilizați în curba AUC și ROC
- Relația dintre sensibilitate, specificitate, FPR și prag.
- Cum funcționează AUC-ROC?
- Când ar trebui să folosim metrica de evaluare AUC-ROC?
- Speculând performanța modelului
- Înțelegerea curbei AUC-ROC
- Implementare folosind două modele diferite
- Cum se utilizează ROC-AUC pentru un model cu mai multe clase?
- Întrebări frecvente pentru AUC ROC Curve în Machine Learning
Ce este curba AUC-ROC?
Curba AUC-ROC, sau curba Ariei sub caracteristica de funcționare a receptorului, este o reprezentare grafică a performanței unui model de clasificare binar la diferite praguri de clasificare. Este folosit în mod obișnuit în învățarea automată pentru a evalua capacitatea unui model de a distinge între două clase, de obicei clasa pozitivă (de exemplu, prezența unei boli) și clasa negativă (de exemplu, absența unei boli).
Să înțelegem mai întâi semnificația celor doi termeni ROC și AUC .
- ROC : Caracteristici de funcționare a receptorului
- AUC : Zona sub curbă
Curba caracteristicilor de funcționare a receptorului (ROC).
ROC înseamnă Caracteristici de funcționare a receptorului, iar curba ROC este reprezentarea grafică a eficacității modelului de clasificare binar. Acesta prezintă rata pozitivă adevărată (TPR) față de rata pozitivă fals (FPR) la diferite praguri de clasificare.
Zona sub curbă Curba (AUC):
AUC reprezintă zona de sub curbă, iar curba AUC reprezintă aria de sub curba ROC. Măsoară performanța generală a modelului de clasificare binar. Întrucât TPR și FPR variază între 0 și 1, zona va fi întotdeauna între 0 și 1, iar o valoare mai mare a AUC denotă o performanță mai bună a modelului. Scopul nostru principal este de a maximiza această zonă pentru a avea cel mai mare TPR și cel mai mic FPR la pragul dat. AUC măsoară probabilitatea ca modelul să atribuie unei instanțe pozitive alese aleatoriu o probabilitate estimată mai mare în comparație cu o instanță negativă aleasă aleatoriu.
Reprezintă probabilitate cu care modelul nostru poate distinge între cele două clase prezente în ținta noastră.
ROC-AUC Clasificare Evaluare Metrica
Termeni cheie utilizați în curba AUC și ROC
1. TPR și FPR
Aceasta este cea mai comună definiție pe care ați fi întâlnit-o când ați fi folosit pe Google AUC-ROC. Practic, curba ROC este un grafic care arată performanța unui model de clasificare la toate pragurile posibile (pragul este o anumită valoare dincolo de care spuneți că un punct aparține unei anumite clase). Curba este trasată între doi parametri
- TPR – Rata pozitivă adevărată
- FPR – Rata fals pozitivă
Înainte de a înțelege, TPR și FPR ne permit să ne uităm rapid la matricea de confuzie .
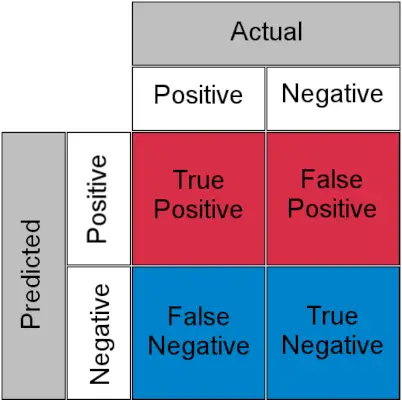
Matrice de confuzie pentru o sarcină de clasificare
- Adevărat pozitiv : Pozitiv real și prezis ca pozitiv
- Adevărat negativ : Negativ real și Predict ca negativ
- Fals pozitiv (Eroare de tip I) : Negativ real, dar prezis ca fiind pozitiv
- Fals Negativ (Eroare de tip II) : Pozitiv real, dar estimat ca negativ
În termeni simpli, puteți numi fals pozitiv a alarma falsa și fals negativ a domnisoara . Acum să ne uităm la ce sunt TPR și FPR.
2. Sensibilitate / Rată pozitivă adevărată / Rechemare
Practic, TPR/Recall/Sensitivity este raportul dintre exemplele pozitive care sunt identificate corect. Reprezintă capacitatea modelului de a identifica corect cazurile pozitive și se calculează după cum urmează:

Sensibilitatea/Rechemarea/TPR măsoară proporția de instanțe pozitive reale care sunt identificate corect de model ca fiind pozitive.
3. Rata fals pozitive
FPR este raportul dintre exemplele negative care sunt clasificate incorect.

4. Specificitatea
Specificitatea măsoară proporția de instanțe negative reale care sunt identificate corect de model ca fiind negative. Reprezintă capacitatea modelului de a identifica corect cazurile negative

Și, după cum sa spus mai devreme, ROC nu este altceva decât graficul dintre TPR și FPR pe toate pragurile posibile, iar AUC este întreaga zonă de sub această curbă ROC.
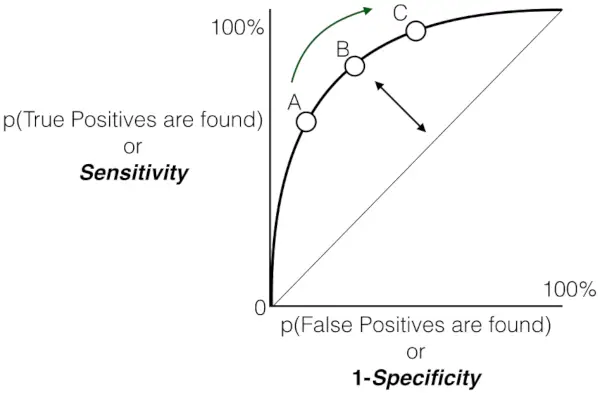
Graficul Sensibilitate versus Rata Fals Pozitiv
Relația dintre sensibilitate, specificitate, FPR și prag .
Sensibilitate și specificitate:
- Relatie inversa: sensibilitatea și specificitatea au o relație inversă. Când unul crește, celălalt tinde să scadă. Acest lucru reflectă compromisul inerent dintre ratele adevărate pozitive și adevărate negative.
- Reglare prin prag: Prin ajustarea valorii prag, putem controla echilibrul dintre sensibilitate și specificitate. Pragurile mai mici conduc la o sensibilitate mai mare (mai multe pozitive adevărate) în detrimentul specificității (mai multe pozitive false). În schimb, creșterea pragului crește specificitatea (mai puține false pozitive), dar sacrifică sensibilitatea (mai multe false negative).
Pragul și rata fals pozitive (FPR):
- Conexiune FPR și specificitate: Rata fals pozitivă (FPR) este pur și simplu complementul specificității (FPR = 1 – specificitate). Aceasta semnifică relația directă dintre ele: specificitatea mai mare se traduce printr-un FPR mai scăzut și invers.
- Modificări FPR cu TPR: În mod similar, după cum ați observat, rata pozitivă adevărată (TPR) și FPR sunt, de asemenea, legate. O creștere a TPR (mai multe pozitive adevărate) duce, în general, la o creștere a FPR (mai multe pozitive false). În schimb, o scădere a TPR (mai puține pozitive adevărate) are ca rezultat o scădere a FPR (mai puține pozitive false)
Cum funcționează AUC-ROC?
Ne-am uitat la interpretarea geometrică, dar cred că încă nu este suficientă în dezvoltarea intuiției din spatele a ceea ce înseamnă de fapt 0,75 AUC, acum să ne uităm la AUC-ROC din punct de vedere probabilistic. Să vorbim mai întâi despre ceea ce face AUC și mai târziu ne vom construi înțelegerea pe deasupra
AUC măsoară cât de bine este un model capabil să facă distincția între clase.
Un AUC de 0,75 ar însemna de fapt că să presupunem că luăm două puncte de date aparținând unor clase separate, atunci există o șansă de 75% ca modelul să le poată separa sau să le ordoneze corect, adică punctul pozitiv are o probabilitate de predicție mai mare decât cel negativ. clasă. (presupunând o probabilitate de predicție mai mare înseamnă că punctul ar aparține în mod ideal clasei pozitive). Iată un mic exemplu pentru a clarifica lucrurile.
Index | Clasă | Probabilitate |
|---|---|---|
P1 | 1 | 0,95 |
P2 | 1 | 0,90 |
P3 | 0 | 0,85 |
P4 | 0 | 0,81 |
P5 | 1 | 0,78 |
P6 | 0 | 0,70 |
Aici avem 6 puncte în care P1, P2 și P5 aparțin clasei 1 și P3, P4 și P6 aparțin clasei 0 și avem probabilități prezise corespunzătoare în coloana Probabilitate, așa cum am spus dacă luăm două puncte aparținând separate. clasele atunci care este probabilitatea ca rangul modelului să le ordoneze corect.
Vom lua toate perechile posibile astfel încât un punct să aparțină clasei 1 și celălalt să aparțină clasei 0, vom avea un total de 9 astfel de perechi mai jos sunt toate aceste 9 perechi posibile.
Pereche | este corect |
|---|---|
(P1,P3) | da |
(P1,P4) | da |
(P1,P6) | da |
(P2,P3) | da |
(P2,P4) | da |
(P2,P6) | da |
(P3,P5) | Nu |
(P4,P5) | Nu |
(P5,P6) | da |
Aici coloana este Corect indică dacă perechea menționată este ordonată corect în funcție de probabilitatea prezisă, adică punctul 1 are o probabilitate mai mare decât punctul 0, în 7 din aceste 9 perechi posibile clasa 1 este clasată mai sus decât clasa 0, sau putem spune că există o șansă de 77% ca dacă alegeți o pereche de puncte aparținând unor clase separate, modelul să le poată distinge corect. Acum, cred că s-ar putea să aveți un pic de intuiție în spatele acestui număr AUC, doar pentru a clarifica orice îndoială ulterioară, hai să-l validăm folosind implementarea Scikit învață AUC-ROC.
Python3
import> numpy as np> from> sklearn .metrics>import> roc_auc_score> y_true>=> [>1>,>1>,>0>,>0>,>1>,>0>]> y_pred>=> [>0.95>,>0.90>,>0.85>,>0.81>,>0.78>,>0.70>]> auc>=> np.>round>(roc_auc_score(y_true, y_pred),>3>)> print>(>'Auc for our sample data is {}'>.>format>(auc))> |
>
>
Ieșire:
AUC for our sample data is 0.778>
Când ar trebui să folosim metrica de evaluare AUC-ROC?
Există unele zone în care utilizarea ROC-AUC ar putea să nu fie ideală. În cazurile în care setul de date este foarte dezechilibrat, curba ROC poate oferi o evaluare prea optimistă a performanței modelului . Această părtinire de optimism apare deoarece rata de fals pozitive (FPR) a curbei ROC poate deveni foarte mică atunci când numărul de negative reale este mare.
Privind formula FPR,

observăm ,
- Clasa Negativă este majoritară, numitorul FPR este dominat de Adevărații Negative, din cauza cărora FPR devine mai puțin sensibilă la modificările predicțiilor legate de clasa minoritară (clasa pozitivă).
- Curbele ROC pot fi adecvate atunci când costul Fals Pozitive și Fals Negative este echilibrat și setul de date nu este puternic dezechilibrat.
In acest caz, Curbe de precizie-rechemare pot fi utilizate care oferă o metrică de evaluare alternativă, care este mai potrivită pentru seturile de date dezechilibrate, concentrându-se pe performanța clasificatorului în raport cu clasa pozitivă (minoritară).
Speculând performanța modelului
- Un AUC ridicat (aproape de 1) indică o putere de discriminare excelentă. Aceasta înseamnă că modelul este eficient în a face distincția între cele două clase, iar predicțiile sale sunt de încredere.
- Un AUC scăzut (aproape de 0) sugerează o performanță slabă. În acest caz, modelul se luptă să facă diferența între clasele pozitive și cele negative, iar previziunile sale pot să nu fie demne de încredere.
- AUC în jur de 0,5 implică faptul că modelul face, în esență, presupuneri aleatorii. Nu arată nicio capacitate de a separa clasele, ceea ce indică faptul că modelul nu învață niciun model semnificativ din date.
Înțelegerea curbei AUC-ROC
Într-o curbă ROC, axa x reprezintă de obicei rata fals pozitivă (FPR), iar axa y reprezintă rata pozitivă adevărată (TPR), cunoscută și sub numele de Sensibilitate sau Recall. Deci, o valoare mai mare a axei x (spre dreapta) pe curba ROC indică o rată fals pozitivă mai mare, iar o valoare mai mare a axei y (spre sus) indică o rată pozitivă adevărată mai mare. Curba ROC este un grafic reprezentarea compromisului dintre rata pozitivă adevărată și rata pozitivă fals la diferite praguri. Acesta arată performanța unui model de clasificare la diferite praguri de clasificare. AUC (Area Under the Curve) este o măsură sumară a performanței curbei ROC. Alegerea pragului depinde de cerințele specifice ale problemei pe care încercați să o rezolvați și de compromisul dintre fals pozitive și false negative care este acceptabil în contextul dvs.
- Dacă doriți să acordați prioritate reducerii fals-pozitive (minimizarea șanselor de a eticheta ceva ca pozitiv atunci când nu este), puteți alege un prag care are ca rezultat o rată mai mică de fals pozitive.
- Dacă doriți să acordați prioritate creșterii valorilor pozitive adevărate (capturarea a cât mai multe pozitive reale posibil), puteți alege un prag care are ca rezultat o rată pozitivă adevărată mai mare.
Să luăm în considerare un exemplu pentru a ilustra modul în care curbele ROC sunt generate pentru diferite praguri și modul în care un anumit prag corespunde unei matrice de confuzie. Să presupunem că avem un problema de clasificare binară cu un model care prezice dacă un e-mail este spam (pozitiv) sau nu spam (negativ).
Să luăm în considerare datele ipotetice,
Etichete adevărate: [1, 0, 1, 0, 1, 1, 0, 0, 1, 0]
Probabilități estimate: [0,8, 0,3, 0,6, 0,2, 0,7, 0,9, 0,4, 0,1, 0,75, 0,55]
Cazul 1: Pragul = 0,5
Etichete adevărate | Probabilități prezise | Etichete estimate |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Matrice de confuzie bazată pe predicțiile de mai sus
| Predicție = 0 | Predicție = 1 |
|---|---|---|
Real = 0 | TP=4 | FN=1 |
Real = 1 | FP=0 | TN=5 |
În consecinţă,
- Rata adevărată pozitivă (TPR) :
Proporția pozitivelor reale identificate corect de către clasificator este

- Rata fals pozitive (FPR) :
Proporția de negative reale clasificate incorect drept pozitive



Deci, la pragul de 0,5:
- Rată pozitivă adevărată (sensibilitate): 0,8
- Rata fals pozitive: 0
Interpretarea este că modelul, la acest prag, identifică corect 80% din pozitivele reale (TPR), dar clasifică incorect 0% dintre negativele reale ca pozitive (FPR).
În consecință, pentru diferite praguri vom obține,
Cazul 2: Pragul = 0,7
Etichete adevărate | Probabilități prezise | Etichete estimate |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 0 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 0 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 0 |
Matrice de confuzie bazată pe predicțiile de mai sus
| Predicție = 0 | Predicție = 1 |
|---|---|---|
Real = 0 | TP=5 | FN=0 |
Real = 1 | FP=2 | TN=3 |
În consecinţă,
- Rata adevărată pozitivă (TPR) :
Proporția pozitivelor reale identificate corect de către clasificator este

- Rata fals pozitive (FPR) :
Proporția de negative reale clasificate incorect drept pozitive



Cazul 3: Pragul = 0,4
Etichete adevărate | Probabilități prezise | Etichete estimate |
|---|---|---|
| 1 vlc media player descărca youtube | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Matrice de confuzie bazată pe predicțiile de mai sus
| Predicție = 0 | Predicție = 1 |
|---|---|---|
Real = 0 | TP=4 | FN=1 |
Real = 1 | FP=0 | TN=5 |
În consecinţă,
- Rata adevărată pozitivă (TPR) :
Proporția pozitivelor reale identificate corect de către clasificator este
- Rata fals pozitive (FPR) :
Proporția de negative reale clasificate incorect drept pozitive
Cazul 4: Pragul = 0,2
Etichete adevărate | Probabilități prezise | Etichete estimate |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 1 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 1 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Matrice de confuzie bazată pe predicțiile de mai sus
| Predicție = 0 | Predicție = 1 |
|---|---|---|
Real = 0 | TP=2 | FN=3 |
Real = 1 | FP=0 | TN=5 |
În consecinţă,
- Rata adevărată pozitivă (TPR) :
Proporția pozitivelor reale identificate corect de către clasificator este

- Rata fals pozitive (FPR) :
Proporția de negative reale clasificate incorect drept pozitive

Cazul 5: Pragul = 0,85
Etichete adevărate | Probabilități prezise | Etichete estimate |
|---|---|---|
| 1 | 0,8 | 0 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 0 |
| 0 | 0,2 | 0 |
| 1 | 0,7 ce este comanda de export în linux | 0 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 0 |
| 0 | 0,55 | 0 |
Matrice de confuzie bazată pe predicțiile de mai sus
| Predicție = 0 | Predicție = 1 |
|---|---|---|
Real = 0 | TP=5 | FN=0 |
Real = 1 | FP=4 | TN=1 |
În consecinţă,
- Rata adevărată pozitivă (TPR) :
Proporția pozitivelor reale identificate corect de către clasificator este
- Rata fals pozitive (FPR) :
Proporția de negative reale clasificate incorect drept pozitive


Pe baza rezultatului de mai sus, vom trasa curba ROC
Python3
true_positive_rate>=> [>0.4>,>0.8>,>0.8>,>1.0>,>1>]> false_positive_rate>=> [>0>,>0>,>0>,>0.2>,>0.8>]> plt.plot(false_positive_rate, true_positive_rate,>'o-'>, label>=>'ROC'>)> plt.plot([>0>,>1>], [>0>,>1>],>'--'>, color>=>'grey'>, label>=>'Worst case'>)> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curve'>)> plt.legend()> plt.show()> |
>
>
Ieșire:
Din grafic rezultă că:
- Linia gri întreruptă reprezintă scenariul cel mai rău caz, în care predicțiile modelului, adică TPR sunt FPR, sunt aceleași. Această linie diagonală este considerată cel mai rău scenariu, indicând o probabilitate egală de fals pozitive și fals negative.
- Pe măsură ce punctele se abat de la linia de estimare aleatorie către colțul din stânga sus, performanța modelului se îmbunătățește.
- Aria de sub curbă (AUC) este o măsură cantitativă a capacității de discriminare a modelului. O valoare AUC mai mare, mai aproape de 1,0, indică performanță superioară. Cea mai bună valoare AUC posibilă este 1,0, corespunzătoare unui model care atinge 100% sensibilitate și 100% specificitate.
În total, curba caracteristică de funcționare a receptorului (ROC) servește ca o reprezentare grafică a compromisului dintre rata pozitivă adevărată (sensibilitate) și rata pozitivă falsă a unui model de clasificare binar la diferite praguri de decizie. Pe măsură ce curba urcă grațios spre colțul din stânga sus, semnifică capacitatea lăudabilă a modelului de a discrimina între cazurile pozitive și negative pe o serie de praguri de încredere. Această traiectorie ascendentă indică o performanță îmbunătățită, cu o sensibilitate mai mare atinsă în același timp minimizând fals pozitive. Pragurile adnotate, notate ca A, B, C, D și E, oferă informații valoroase asupra comportamentului dinamic al modelului la diferite niveluri de încredere.
Implementare folosind două modele diferite
Instalarea Bibliotecilor
Python3
import> numpy as np> import> pandas as pd> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> |
>
>
Pentru a-l antrena pe Pădurea aleatorie și Regresie logistică modele și pentru a-și prezenta curbele ROC cu scoruri AUC, algoritmul creează date artificiale de clasificare binară.
Generarea datelor și împărțirea datelor
Python3
# Generate synthetic data for demonstration> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>2>, random_state>=>42>)> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y, test_size>=>0.2>, random_state>=>42>)> |
>
>
Folosind un raport de împărțire 80-20, algoritmul creează date artificiale de clasificare binară cu 20 de caracteristici, le împarte în seturi de antrenament și testare și atribuie o sămânță aleatorie pentru a asigura reproductibilitatea.
Antrenarea diferitelor modele
Python3
# Train two different models> logistic_model>=> LogisticRegression(random_state>=>42>)> logistic_model.fit(X_train, y_train)> random_forest_model>=> RandomForestClassifier(n_estimators>=>100>, random_state>=>42>)> random_forest_model.fit(X_train, y_train)> |
>
>
Folosind o sămânță aleatorie fixă pentru a asigura repetabilitatea, metoda inițializează și antrenează un model de regresie logistică pe setul de antrenament. În mod similar, folosește datele de antrenament și aceeași sămânță aleatoare pentru a inițializa și a antrena un model de pădure aleatorie cu 100 de copaci.
Previziuni
Python3
# Generate predictions> y_pred_logistic>=> logistic_model.predict_proba(X_test)[:,>1>]> y_pred_rf>=> random_forest_model.predict_proba(X_test)[:,>1>]> |
>
>
Folosind datele de testare și un antrenat Regresie logistică model, codul prezice probabilitatea clasei pozitive. Într-o manieră similară, folosind datele de testare, utilizează modelul de pădure aleatorie antrenat pentru a produce probabilități proiectate pentru clasa pozitivă.
Crearea unui cadru de date
Python3
# Create a DataFrame> test_df>=> pd.DataFrame(> >{>'True'>: y_test,>'Logistic'>: y_pred_logistic,>'RandomForest'>: y_pred_rf})> |
>
>
Folosind datele de testare, codul creează un DataFrame numit test_df cu coloane etichetate True, Logistic și RandomForest, adăugând etichete adevărate și probabilități prezise din modelele Random Forest și Logistic Regression.
Trasează curba ROC pentru modele
Python3
# Plot ROC curve for each model> plt.figure(figsize>=>(>7>,>5>))> for> model>in> [>'Logistic'>,>'RandomForest'>]:> >fpr, tpr, _>=> roc_curve(test_df[>'True'>], test_df[model])> >roc_auc>=> auc(fpr, tpr)> >plt.plot(fpr, tpr, label>=>f>'{model} (AUC = {roc_auc:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'r--'>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curves for Two Models'>)> plt.legend()> plt.show()> |
>
>
Ieșire:

Codul generează un complot cu cifre de 8 pe 6 inci. Acesta calculează curba AUC și ROC pentru fiecare model (Random Forest and Logistic Regression), apoi trasează curba ROC. The curba ROC pentru ghicirea aleatorie este reprezentată și de o linie roșie întreruptă, iar etichetele, un titlu și o legendă sunt setate pentru vizualizare.
Cum se utilizează ROC-AUC pentru un model cu mai multe clase?
Pentru o setare cu mai multe clase, putem folosi pur și simplu metodologia one vs all și veți avea o curbă ROC pentru fiecare clasă. Să presupunem că aveți patru clase A, B, C și D, atunci ar exista curbe ROC și valori AUC corespunzătoare pentru toate cele patru clase, adică odată ce A ar fi o clasă și B, C și D combinate ar fi celelalte clase. , în mod similar, B este o clasă și A, C și D combinate ca alte clase etc.
Pașii generali pentru utilizarea AUC-ROC în contextul unui model de clasificare multiclasă sunt:
Metodologia One-vs-All:
- Pentru fiecare clasă din problema multiclasă, tratați-o ca pe o clasă pozitivă, combinând toate celelalte clase în clasa negativă.
- Antrenează clasificatorul binar pentru fiecare clasă față de restul claselor.
Calculați AUC-ROC pentru fiecare clasă:
- Aici trasăm curba ROC pentru clasa dată față de restul.
- Trasează curbele ROC pentru fiecare clasă pe același grafic. Fiecare curbă reprezintă performanța de discriminare a modelului pentru o anumită clasă.
- Examinați scorurile AUC pentru fiecare clasă. Un scor AUC mai mare indică o mai bună discriminare pentru acea clasă particulară.
Implementarea AUC-ROC în clasificarea multiclasă
Import de biblioteci
Python3
import> numpy as np> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.preprocessing>import> label_binarize> from> sklearn.multiclass>import> OneVsRestClassifier> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> from> itertools>import> cycle> |
>
>
Programul creează date artificiale multiclasă, le împarte în seturi de antrenament și testare și apoi utilizează One-vs-Restclassifier tehnică de instruire a clasificatorilor atât pentru pădure aleatoare, cât și pentru regresia logistică. În cele din urmă, grafică curbele ROC multiclasă ale celor două modele pentru a demonstra cât de bine discriminează între diferitele clase.
Generarea datelor și împărțirea
Python3
# Generate synthetic multiclass data> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>3>, n_informative>=>10>, random_state>=>42>)> # Binarize the labels> y_bin>=> label_binarize(y, classes>=>np.unique(y))> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y_bin, test_size>=>0.2>, random_state>=>42>)> |
>
>
Trei clase și douăzeci de caracteristici alcătuiesc datele sintetice multiclase produse de cod. După binarizarea etichetelor, datele sunt împărțite în seturi de antrenament și testare într-un raport de 80-20.
Modele de antrenament
Python3
# Train two different multiclass models> logistic_model>=> OneVsRestClassifier(LogisticRegression(random_state>=>42>))> logistic_model.fit(X_train, y_train)> rf_model>=> OneVsRestClassifier(> >RandomForestClassifier(n_estimators>=>100>, random_state>=>42>))> rf_model.fit(X_train, y_train)> |
>
>
Programul antrenează două modele multiclase: un model Random Forest cu 100 de estimatori și un model de regresie logistică cu Abordarea unu-vs-odihnă . Cu setul de date de antrenament, ambele modele sunt montate.
Trasarea curbei AUC-ROC
Python3
# Compute ROC curve and ROC area for each class> fpr>=> dict>()> tpr>=> dict>()> roc_auc>=> dict>()> models>=> [logistic_model, rf_model]> plt.figure(figsize>=>(>6>,>5>))> colors>=> cycle([>'aqua'>,>'darkorange'>])> for> model, color>in> zip>(models, colors):> >for> i>in> range>(model.classes_.shape[>0>]):> >fpr[i], tpr[i], _>=> roc_curve(> >y_test[:, i], model.predict_proba(X_test)[:, i])> >roc_auc[i]>=> auc(fpr[i], tpr[i])> >plt.plot(fpr[i], tpr[i], color>=>color, lw>=>2>,> >label>=>f>'{model.__class__.__name__} - Class {i} (AUC = {roc_auc[i]:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'k--'>, lw>=>2>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'Multiclass ROC Curve with Logistic Regression and Random Forest'>)> plt.legend(loc>=>'lower right'>)> plt.show()> |
>
>
Ieșire:

Curbele ROC și scorurile AUC ale modelelor de pădure aleatoare și regresie logistică sunt calculate de codul pentru fiecare clasă. Curbele ROC multiclase sunt apoi trasate, arătând performanța de discriminare a fiecărei clase și prezentând o linie care reprezintă ghicirea aleatorie. Graficul rezultat oferă o evaluare grafică a performanței de clasificare a modelelor.
Concluzie
În învățarea automată, performanța modelelor de clasificare binară este evaluată folosind o metrică crucială numită Zona sub caracteristica de funcționare a receptorului (AUC-ROC). Pe diferite praguri de decizie, arată cum se schimbă sensibilitatea și specificitatea. O discriminare mai mare între cazurile pozitive și negative este de obicei prezentată de un model cu un scor AUC mai mare. În timp ce 0,5 înseamnă șansă, 1 reprezintă performanță impecabilă. Optimizarea și selecția modelului sunt ajutate de informațiile utile pe care le oferă curba AUC-ROC despre capacitatea unui model de a discrimina între clase. Când lucrați cu seturi de date sau aplicații neechilibrate în care falsele pozitive și false negative au costuri diferite, este deosebit de utilă ca măsură cuprinzătoare.
Întrebări frecvente pentru AUC ROC Curve în Machine Learning
1. Ce este curba AUC-ROC?
Pentru diferite praguri de clasificare, compromisul dintre rata pozitivă adevărată (sensibilitate) și rata pozitivă fals (specificitate) este reprezentată grafic de curba AUC-ROC.
2. Cum arată o curbă AUC-ROC perfectă?
O zonă de 1 pe o curbă ideală AUC-ROC ar însemna că modelul atinge sensibilitate și specificitate optime la toate pragurile.
3. Ce înseamnă o valoare AUC de 0,5?
AUC de 0,5 indică faptul că performanța modelului este comparabilă cu cea a șanselor aleatorii. Ea sugerează o lipsă de capacitate de discriminare.
4. Poate fi utilizat AUC-ROC pentru clasificarea multiclasă?
AUC-ROC se aplică frecvent problemelor care implică clasificarea binară. Variații precum macro-medie sau micro-medie AUC pot fi luate în considerare pentru clasificarea multiclasă.
5. Cum este utilă curba AUC-ROC în evaluarea modelului?
Capacitatea unui model de a discrimina între clase este rezumată complet de curba AUC-ROC. Când lucrați cu seturi de date neechilibrate, este deosebit de util.