Ingrijitor zoo este un serviciu de coordonare distribuit, open-source pentru aplicații distribuite. Expune un set simplu de primitive pentru a implementa servicii de nivel superior pentru sincronizare, întreținere a configurației și grupare și denumire.
Într-un sistem distribuit, există mai multe noduri sau mașini care trebuie să comunice între ele și să își coordoneze acțiunile. ZooKeeper oferă o modalitate de a se asigura că aceste noduri sunt conștiente unul de celălalt și își pot coordona acțiunile. Face acest lucru prin menținerea unui arbore ierarhic de noduri de date numite Znodes , care poate fi folosit pentru a stoca și a prelua date și pentru a menține informațiile despre stare. ZooKeeper oferă un set de primitive, cum ar fi încuietori, bariere și cozi, care pot fi folosite pentru a coordona acțiunile nodurilor dintr-un sistem distribuit. De asemenea, oferă funcții precum alegerea liderului, failoverul și recuperarea, care pot ajuta la asigurarea rezistenței sistemului la eșecuri. ZooKeeper este utilizat pe scară largă în sistemele distribuite precum Hadoop, Kafka și HBase și a devenit o componentă esențială a multor aplicații distribuite.
De ce avem nevoie de ea?
- Servicii de coordonare : Integrarea/comunicarea serviciilor într-un mediu distribuit.
- Serviciile de coordonare sunt complexe pentru a fi corectate. Sunt în mod special predispuși la erori, cum ar fi condițiile de cursă și blocarea.
- Stare de cursă -Două sau mai multe sisteme care încearcă să îndeplinească o anumită sarcină.
- Blocaje – Două sau mai multe operațiuni se așteaptă una pe cealaltă.
- Pentru a facilita coordonarea dintre mediile distribuite, dezvoltatorii au venit cu o idee numită zookeeper, astfel încât să nu fie nevoiți să scutească aplicațiile distribuite de responsabilitatea implementării serviciilor de coordonare de la zero.
Ce este sistemul distribuit?
- Mai multe sisteme informatice care lucrează la o singură problemă.
- Este o rețea care constă din calculatoare autonome care sunt conectate folosind middleware distribuit.
- Caracteristici cheie : Concurent, partajarea resurselor, independent, global, toleranță mai mare la erori și raportul preț/performanță este mult mai bun.
- Scopul cheie s: Transparență, Fiabilitate, Performanță, Scalabilitate.
- Provocări : securitate, erori, coordonare și partajare a resurselor.
Provocarea coordonării
- De ce este coordonarea într-un sistem distribuit problema grea?
- Managementul coordonării sau configurării pentru o aplicație distribuită care are multe sisteme.
- Nodul principal unde sunt stocate datele clusterului.
- Nodurile de lucru sau nodurile slave primesc datele de la acest nod master.
- un singur punct de eșec.
- sincronizarea nu este ușoară.
- Este nevoie de proiectare și implementare atentă.
Apache Zookeeper
Apache Zookeeper este un serviciu de coordonare distribuit, open-source pentru sisteme distribuite. Oferă un loc central pentru aplicațiile distribuite pentru stocarea datelor, comunicarea între ele și coordonarea activităților. Zookeeper este utilizat în sistemele distribuite pentru a coordona procesele și serviciile distribuite. Oferă un model de date simplu, structurat în arbore, un API simplu și un protocol distribuit pentru a asigura consistența și disponibilitatea datelor. Zookeeper este proiectat pentru a fi foarte fiabil și tolerant la erori și poate gestiona niveluri ridicate de debit de citire și scriere.
Zookeeper este implementat în Java și este utilizat pe scară largă în sistemele distribuite, în special în ecosistemul Hadoop. Este un proiect Apache Software Foundation și este lansat sub licența Apache 2.0.
Arhitectura Zookeeperului
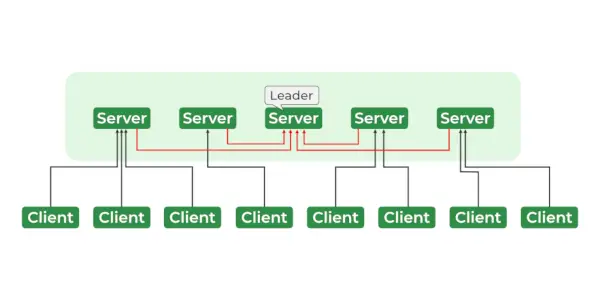
Servicii zookeeper
Arhitectura ZooKeeper constă dintr-o ierarhie de noduri numite znodes, organizate într-o structură arborescentă. Fiecare znode poate stoca date și are un set de permisiuni care controlează accesul la znode. Znodes-urile sunt organizate într-un spațiu de nume ierarhic, similar unui sistem de fișiere. La rădăcina ierarhiei se află rădăcina znode, iar toate celelalte znodes sunt copii ale rădăcinii znode. Ierarhia este similară cu o ierarhie a sistemului de fișiere, în care fiecare znode poate avea copii și nepoți și așa mai departe.
Componente importante în Zookeeper
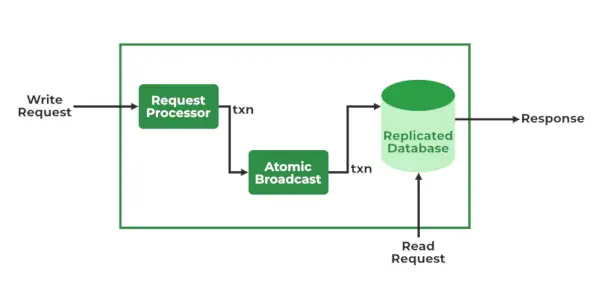
Servicii ZooKeeper
- Lider și urmaș
- Procesor de cereri – Activ în Leader Node și este responsabil pentru procesarea cererilor de scriere. După procesare, trimite modificări la nodurile urmăritoare
- Atomic Broadcast – Prezent atât în Nodul Leader, cât și în Nodul Follower. Este responsabil pentru trimiterea modificărilor către alte noduri.
- Baze de date în memorie (Baze de date replicate)-Este responsabil pentru stocarea datelor în zookeeper. Fiecare nod conține propriile baze de date. Datele sunt, de asemenea, scrise în sistemul de fișiere, oferind recuperabilitate în cazul oricăror probleme cu clusterul.
Alte componente
- Client – Unul dintre nodurile din clusterul nostru de aplicații distribuite. Accesați informații de pe server. Fiecare client trimite un mesaj serverului pentru a-i anunța pe server că clientul este în viață.
- Server – Oferă clientului toate serviciile. Oferă recunoaștere clientului.
- Ansamblu – Grup de servere Zookeeper. Numărul minim de noduri care sunt necesare pentru a forma un ansamblu este 3.
Modelul de date Zookeeper
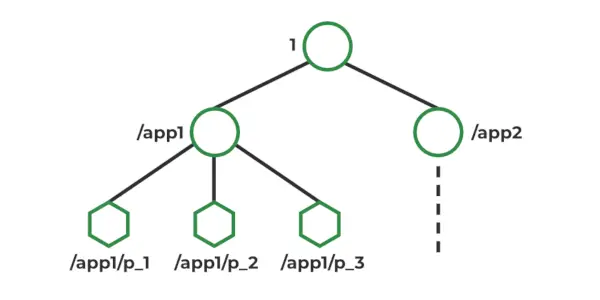
Model de date ZooKeeper
În Zookeeper, datele sunt stocate într-un spațiu de nume ierarhic, similar unui sistem de fișiere. Fiecare nod din spațiul de nume este numit Znode și poate stoca date și poate avea copii. Znodes sunt similare cu fișierele și directoarele dintr-un sistem de fișiere. Zookeeper oferă un API simplu pentru crearea, citirea, scrierea și ștergerea Znodes. De asemenea, oferă mecanisme pentru detectarea modificărilor datelor stocate în Znodes, cum ar fi ceasurile și declanșatoarele. Znodes menține o structură statistică care include: numărul versiunii, ACL, timestamp, lungimea datelor
Tipuri de Znodes :
- Persistenţă : în viață până când sunt șterse în mod explicit.
- Efemer : Activ până când conexiunea client este activă.
- Secvenţial : Fie persistent, fie efemer.
De ce avem nevoie de ZooKeeper în Hadoop?
Zookeeper este folosit pentru a gestiona și coordona nodurile dintr-un cluster Hadoop, inclusiv NameNode, DataNode și ResourceManager. Într-un cluster Hadoop, Zookeeper ajută la:
- Mențineți informațiile de configurare: Zookeeper stochează informațiile de configurare pentru clusterul Hadoop, inclusiv locația NameNode, DataNode și ResourceManager.
- Gestionați starea clusterului: Zookeeper urmărește starea nodurilor din clusterul Hadoop și poate fi folosit pentru a detecta când un nod a eșuat sau a devenit indisponibil.
- Coordonarea proceselor distribuite: Zookeeper poate fi folosit pentru a coordona procesele distribuite, cum ar fi programarea lucrărilor și alocarea resurselor, între nodurile dintr-un cluster Hadoop.
Zookeeper ajută la asigurarea disponibilității și fiabilității unui cluster Hadoop prin furnizarea unui serviciu central de coordonare pentru nodurile din cluster.
Cum funcționează ZooKeeper în Hadoop?
ZooKeeper funcționează ca un sistem de fișiere distribuit și expune un set simplu de API-uri care permit clienților să citească și să scrie date în sistemul de fișiere. Își stochează datele într-o structură arborescentă numită znode, care poate fi considerată ca un fișier sau un director într-un sistem de fișiere tradițional. ZooKeeper folosește un algoritm de consens pentru a se asigura că toate serverele sale au o vedere consecventă asupra datelor stocate în Znodes. Aceasta înseamnă că, dacă un client scrie date pe un znode, acele date vor fi replicate pe toate celelalte servere din ansamblul ZooKeeper.
O caracteristică importantă a ZooKeeper este capacitatea sa de a susține noțiunea de ceas. Un ceas permite unui client să se înregistreze pentru notificări atunci când datele stocate într-un znode se modifică. Acest lucru poate fi util pentru a monitoriza modificările aduse datelor stocate în ZooKeeper și pentru a reacționa la acele modificări într-un sistem distribuit.
În Hadoop, ZooKeeper este utilizat pentru o varietate de scopuri, inclusiv:
- Stocarea informațiilor de configurare: ZooKeeper este utilizat pentru a stoca informații de configurare care sunt partajate de mai multe componente Hadoop. De exemplu, poate fi folosit pentru a stoca locațiile NameNodes într-un cluster Hadoop sau adresele nodurilor JobTracker.
- Furnizarea de sincronizare distribuită: ZooKeeper este utilizat pentru a coordona activitățile diferitelor componente Hadoop și pentru a se asigura că acestea lucrează împreună într-o manieră consecventă. De exemplu, ar putea fi folosit pentru a se asigura că numai un NameNode este activ la un moment dat într-un cluster Hadoop.
- Menținerea denumirii: ZooKeeper este utilizat pentru a menține un serviciu de denumire centralizat pentru componentele Hadoop. Acest lucru poate fi util pentru identificarea și localizarea resurselor într-un sistem distribuit.
ZooKeeper este o componentă esențială a Hadoop și joacă un rol crucial în coordonarea activității diferitelor sale subcomponente.
Citirea și scrierea în Apache Zookeeper
ZooKeeper oferă o interfață simplă și fiabilă pentru citirea și scrierea datelor. Datele sunt stocate într-un spațiu de nume ierarhic, similar unui sistem de fișiere, cu noduri numite znodes. Fiecare znode poate stoca date și poate avea copii znodes. Clienții ZooKeeper pot citi și scrie date pe aceste znodes folosind metodele getData() și, respectiv, setData(). Iată un exemplu de citire și scriere a datelor folosind API-ul ZooKeeper Java:
Java
// Connect to the ZooKeeper ensemble> ZooKeeper zk =>new> ZooKeeper(>'localhost:2181'>,>3000>,>null>);> // Write data to the znode '/myZnode'> String path =>'/myZnode'>;> String data =>'hello world'>;> zk.create(path, data.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);> // Read data from the znode '/myZnode'> byte>[] bytes = zk.getData(path,>false>,>null>);> String readData =>new> String(bytes);> // Prints 'hello world'> System.out.println(readData);> // Closing the connection> // to the ZooKeeper ensemble> zk.close();> |
>
>
Python3
from> kazoo.client>import> KazooClient> # Connect to ZooKeeper> zk>=> KazooClient(hosts>=>'localhost:2181'>)> zk.start()> # Create a node with some data> zk.ensure_path(>'/gfg_node'>)> zk.>set>(>'/gfg_node'>, b>'some_data'>)> # Read the data from the node> data, stat>=> zk.get(>'/gfg_node'>)> print>(data)> # Stop the connection to ZooKeeper> zk.stop()> |
>
powershell mai mic sau egal cu
>
Sesiune și ceasuri
Sesiune
- Solicitările dintr-o sesiune sunt executate în ordine FIFO.
- Odată ce sesiunea este stabilită, atunci sesiune ID este atribuit clientului.
- Clientul trimite batai de inima pentru a menține sesiunea valabilă
- expirarea sesiunii este de obicei reprezentată în milisecunde
Priveste
- Ceasurile sunt mecanisme prin care clienții pot primi notificări despre modificările din Zookeeper
- Clientul poate urmări în timp ce citește un anumit znode.
- Modificările Znodes sunt modificări ale datelor asociate cu znodes sau modificări ale copiilor znode-ului.
- Ceasurile sunt declanșate o singură dată.
- Dacă sesiunea a expirat, ceasurile sunt de asemenea eliminate.