Căutarea neinformată este o clasă de algoritmi de căutare de uz general, care funcționează prin forța brută. Algoritmii de căutare neinformați nu au informații suplimentare despre starea sau spațiul de căutare, în afară de modul de a traversa arborele, așa că este numit și căutare oarbă.
Următoarele sunt diferitele tipuri de algoritmi de căutare neinformați:
1. Căutare pe lățimea întâi:
- Căutarea pe lățime este cea mai comună strategie de căutare pentru a parcurge un arbore sau un grafic. Acest algoritm caută în lățime într-un arbore sau grafic, deci se numește căutare pe lățime.
- Algoritmul BFS începe căutarea de la nodul rădăcină al arborelui și extinde toate nodurile succesoare la nivelul curent înainte de a trece la nodurile de nivelul următor.
- Algoritmul de căutare pe lățimea întâi este un exemplu de algoritm de căutare în grafic general.
- Căutare pe lățime, implementată folosind structura de date FIFO.
Avantaje:
- BFS va oferi o soluție dacă există vreo soluție.
- Dacă există mai multe soluții pentru o anumită problemă, atunci BFS va oferi soluția minimă care necesită cel mai mic număr de pași.
Dezavantaje:
- Necesită multă memorie, deoarece fiecare nivel al arborelui trebuie salvat în memorie pentru a extinde nivelul următor.
- BFS are nevoie de mult timp dacă soluția este departe de nodul rădăcină.
Exemplu:
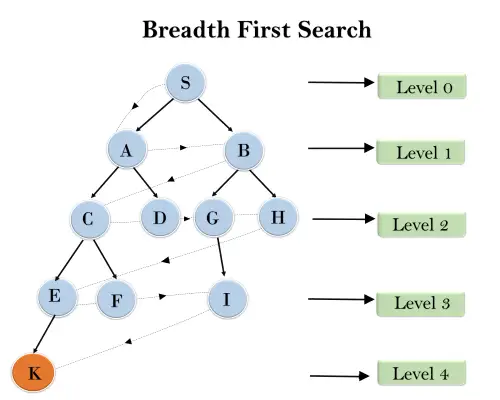
În structura arborescentă de mai jos, am arătat parcurgerea arborelui folosind algoritmul BFS de la nodul rădăcină S la nodul obiectiv K. Algoritmul de căutare BFS traversează în straturi, astfel încât va urma calea care este indicată de săgeata punctată și calea parcursă va fi:
S---> A--->B---->C--->D---->G--->H--->E---->F---->I---->K
Complexitatea timpului: Timpul Complexitatea algoritmului BFS poate fi obținută prin numărul de noduri traversate în BFS până la cel mai puțin adânc nod. Unde d= adâncimea soluției celei mai puțin adânci și b este un nod în fiecare stare.
T (b) = 1+b2+b3+.......+ bd= O (bd)
Complexitatea spațiului: Complexitatea spațială a algoritmului BFS este dată de dimensiunea memoriei frontierei care este O(bd).
Completitudine: BFS este complet, ceea ce înseamnă că dacă cel mai mic nod obiectiv este la o adâncime finită, atunci BFS va găsi o soluție.
Optimitate: BFS este optim dacă costul căii este o funcție nedescrescătoare a adâncimii nodului.
2. Căutare în profunzime
- Căutarea în profunzime este un algoritm recursiv pentru parcurgerea unei structuri de date arborescente sau grafice.
- Se numește căutarea depth-first deoarece începe de la nodul rădăcină și urmează fiecare cale până la nodul de cea mai mare adâncime înainte de a trece la următoarea cale.
- DFS utilizează o structură de date stivă pentru implementarea sa.
- Procesul algoritmului DFS este similar cu algoritmul BFS.
Notă: Backtracking este o tehnică de algoritm pentru găsirea tuturor soluțiilor posibile folosind recursiunea.
Avantaj:
- DFS necesită foarte puțină memorie, deoarece trebuie doar să stocheze o stivă de noduri pe calea de la nodul rădăcină la nodul curent.
- Este nevoie de mai puțin timp pentru a ajunge la nodul obiectiv decât algoritmul BFS (dacă traversează pe calea corectă).
Dezavantaj:
- Există posibilitatea ca multe state să reapară în continuare și nu există nicio garanție a găsirii soluției.
- Algoritmul DFS folosește căutarea profundă și uneori poate merge la bucla infinită.
Exemplu:
În arborele de căutare de mai jos, am arătat fluxul căutării în profunzime și va urma ordinea ca:
Nod rădăcină--->Nod stânga ----> nod dreapta.
Va începe căutarea de la nodul rădăcină S și va traversa A, apoi B, apoi D și E, după ce a traversat E, va întoarce arborele, deoarece E nu are alt succesor și totuși nodul obiectiv nu este găsit. După întoarcere, va traversa nodul C și apoi G și aici se va termina când a găsit nodul obiectiv.

Completitudine: Algoritmul de căutare DFS este complet în spațiul de stări finite, deoarece va extinde fiecare nod într-un arbore de căutare limitat.
Complexitatea timpului: Complexitatea temporală a DFS va fi echivalentă cu nodul traversat de algoritm. Este dat de:
T(n)= 1+ n2+ n3+.........+ nm=O(nm)
Unde, m = adâncimea maximă a oricărui nod și aceasta poate fi mult mai mare decât d (adâncimea cea mai mică a soluției)
Complexitatea spațiului: Algoritmul DFS trebuie să stocheze o singură cale de la nodul rădăcină, prin urmare complexitatea spațială a DFS este echivalentă cu dimensiunea setului marginal, care este O(bm) .
avantajele energiei electrice
Optimal: Algoritmul de căutare DFS nu este optim, deoarece poate genera un număr mare de pași sau un cost ridicat pentru a ajunge la nodul obiectiv.
3. Algoritmul de căutare cu adâncime limitată:
Un algoritm de căutare cu adâncime limitată este similar cu căutarea depth-first cu o limită predeterminată. Căutarea limitată la adâncime poate rezolva dezavantajul căii infinite în căutarea depth first. În acest algoritm, nodul de la limita de adâncime va trata ca nu mai are noduri succesoare.
Căutarea limitată la profunzime poate fi încheiată cu două Condiții de eșec:
- Valoarea standard a eșecului: indică faptul că problema nu are nicio soluție.
- Valoarea eșecului de tăiere: nu definește nicio soluție pentru problemă într-o anumită limită de adâncime.
Avantaje:
material unghiular
Căutarea limitată la profunzime este eficientă pentru memorie.
Dezavantaje:
- Căutarea limitată la profunzime are, de asemenea, un dezavantaj de incompletitudine.
- Este posibil să nu fie optim dacă problema are mai multe soluții.
Exemplu:

Completitudine: Algoritmul de căutare DLS este complet dacă soluția este peste limita de adâncime.
Complexitatea timpului: Complexitatea de timp a algoritmului DLS este O(bℓ) .
Complexitatea spațiului: Complexitatea spațială a algoritmului DLS este O (b�ℓ) .
Optimal: Căutarea limitată la adâncime poate fi privită ca un caz special de DFS și, de asemenea, nu este optimă chiar dacă ℓ>d.
4. Algoritm de căutare cu costuri uniforme:
Căutarea cu costuri uniforme este un algoritm de căutare utilizat pentru a parcurge un arbore sau un grafic ponderat. Acest algoritm intră în joc atunci când este disponibil un cost diferit pentru fiecare margine. Scopul principal al căutării cu costuri uniforme este de a găsi o cale către nodul obiectiv care are cel mai mic cost cumulat. Căutarea cu costuri uniforme extinde nodurile în funcție de costurile lor de cale de la nodul rădăcină. Poate fi folosit pentru a rezolva orice grafic/arbore unde costul optim este solicitat. Un algoritm de căutare cu costuri uniforme este implementat de coada de prioritate. Acordă prioritate maximă celui mai mic cost cumulat. Căutarea uniformă a costurilor este echivalentă cu algoritmul BFS dacă costul căii pentru toate marginile este același.
Avantaje:
- Căutarea uniformă a costurilor este optimă deoarece în fiecare stare este aleasă calea cu cel mai mic cost.
Dezavantaje:
- Nu îi pasă de numărul de pași implicați în căutare și este preocupat doar de costul căii. Datorită faptului că acest algoritm poate fi blocat într-o buclă infinită.
Exemplu:

Completitudine:
Căutarea la costuri uniforme este completă, de exemplu, dacă există o soluție, UCS o va găsi.
Complexitatea timpului:
Fie C* este Costul soluției optime , și e este fiecare pas să se apropie de nodul obiectiv. Atunci numărul de pași este = C*/ε+1. Aici am luat +1, deoarece începem de la starea 0 și terminăm la C*/ε.
Prin urmare, cel mai rău caz complexitatea de timp a căutării cu costuri uniforme este O(b1 + [C*/e])/ .
Complexitatea spațiului:
Aceeași logică este pentru complexitatea spațiului, astfel încât complexitatea spațială în cel mai rău caz al căutării cu costuri uniforme este O(b1 + [C*/e]) .
Optimal:
Căutarea la costuri uniforme este întotdeauna optimă, deoarece selectează doar o cale cu cel mai mic cost de cale.
5. Aprofundare iterativă în profunzime-întâi Căutare:
Algoritmul de aprofundare iterativă este o combinație de algoritmi DFS și BFS. Acest algoritm de căutare află cea mai bună limită de adâncime și o face prin creșterea treptat a limitei până când este găsit un obiectiv.
Acest algoritm efectuează căutarea depth-first până la o anumită „limită de adâncime” și continuă să crească limita de adâncime după fiecare iterație până când este găsit nodul obiectiv.
Acest algoritm de căutare combină beneficiile căutării rapide a căutării pe lățimea întâi și ale eficienței memoriei căutării în profunzime.
Algoritmul de căutare iterativă este util pentru căutarea neinformată atunci când spațiul de căutare este mare și adâncimea nodului obiectiv este necunoscută.
Avantaje:
- Combină beneficiile algoritmului de căutare BFS și DFS în ceea ce privește căutarea rapidă și eficiența memoriei.
Dezavantaje:
- Principalul dezavantaj al IDDFS este că repetă toată munca din faza anterioară.
Exemplu:
Următoarea structură arborescentă arată căutarea iterativă de adâncime în primul rând. Algoritmul IDDFS efectuează diverse iterații până când nu găsește nodul obiectiv. Iterația efectuată de algoritm este dată astfel:

Prima iterație-----> A
A 2-a iterație ----> A, B, C
A treia iterație ------> A, B, D, E, C, F, G
A 4-a iterație ------> A, B, D, H, I, E, C, F, K, G
În a patra iterație, algoritmul va găsi nodul obiectiv.
Completitudine:
Acest algoritm este complet dacă factorul de ramificare este finit.
Complexitatea timpului:
cum se face upgrade java
Să presupunem că b este factorul de ramificare și adâncimea este d, atunci complexitatea timpului în cel mai rău caz este O(bd) .
Complexitatea spațiului:
Complexitatea spațială a IDDFS va fi O(bd) .
Optimal:
Algoritmul IDDFS este optim dacă costul căii este o funcție nedescrescătoare a adâncimii nodului.
6. Algoritm de căutare bidirecțională:
Algoritmul de căutare bidirecțională rulează două căutări simultane, una din starea inițială numită căutare înainte și alta din nodul obiectiv numită căutare înapoi, pentru a găsi nodul obiectiv. Căutarea bidirecțională înlocuiește un singur grafic de căutare cu două subgrafe mici în care unul începe căutarea de la un vârf inițial, iar celălalt pornește de la vârful obiectivului. Căutarea se oprește atunci când aceste două grafice se intersectează.
Căutarea bidirecțională poate folosi tehnici de căutare precum BFS, DFS, DLS etc.
Avantaje:
- Căutarea bidirecțională este rapidă.
- Căutarea bidirecțională necesită mai puțină memorie
Dezavantaje:
- Implementarea arborelui de căutare bidirecțional este dificilă.
Exemplu:
În arborele de căutare de mai jos, se aplică algoritmul de căutare bidirecțională. Acest algoritm împarte un grafic/arbore în două subgrafe. Începe să traverseze de la nodul 1 în direcția înainte și începe de la nodul țintă 16 în direcția înapoi.
Algoritmul se termină la nodul 9 unde se întâlnesc două căutări.

Completitudine: Căutarea bidirecțională este completă dacă folosim BFS în ambele căutări.
Complexitatea timpului: Complexitatea de timp a căutării bidirecționale folosind BFS este O(bd) .
Complexitatea spațiului: Complexitatea spațială a căutării bidirecționale este O(bd) .
Optimal: Căutarea bidirecțională este optimă.