Citim structurile de date liniare ca o matrice, o listă legată, o stivă și o coadă în care toate elementele sunt aranjate într-o manieră secvențială. Diferitele structuri de date sunt utilizate pentru diferite tipuri de date.
Câțiva factori sunt luați în considerare pentru alegerea structurii datelor:
Un copac este, de asemenea, una dintre structurile de date care reprezintă date ierarhice. Să presupunem că vrem să arătăm angajații și pozițiile lor în formă ierarhică, atunci poate fi reprezentat după cum se arată mai jos:
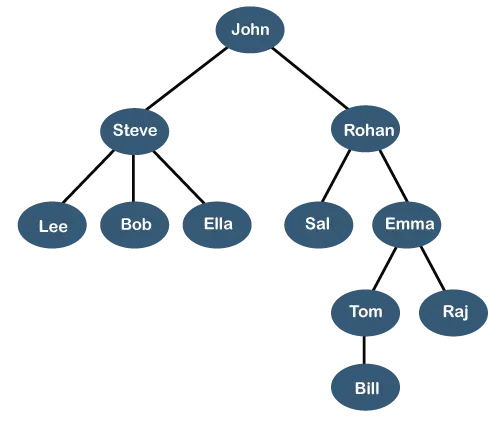
Arborele de mai sus arată ierarhia organizației a unei firme. În structura de mai sus, Ioan este CEO al companiei, iar John are doi raportori direcți numiți ca Steve și Rohan . Steve are trei subordonați direcți numiți Lee, Bob, Ella Unde Steve este manager. Bob are doi raportori direcți numiți Trebuie și Emma . Emma are doi subordonați direcți numiți Tom și Raj . Tom are un raport direct numit Factură . Această structură logică specială este cunoscută ca a Copac . Structura sa este similară cu arborele real, așa că este numit a Copac . În această structură, rădăcină se află în vârf, iar ramurile sale se mișcă în direcție în jos. Prin urmare, putem spune că structura de date Tree este o modalitate eficientă de stocare a datelor într-un mod ierarhic.
Să înțelegem câteva puncte cheie ale structurii de date Tree.
- O structură de date arborescentă este definită ca o colecție de obiecte sau entități cunoscute sub numele de noduri care sunt legate între ele pentru a reprezenta sau simula ierarhia.
- O structură de date arborescentă este o structură de date neliniară deoarece nu este stocată într-o manieră secvenţială. Este o structură ierarhică, deoarece elementele dintr-un arbore sunt aranjate pe mai multe niveluri.
- În structura de date Tree, nodul cel mai de sus este cunoscut ca nod rădăcină. Fiecare nod conține unele date, iar datele pot fi de orice tip. În structura arborescentă de mai sus, nodul conține numele angajatului, deci tipul de date ar fi un șir.
- Fiecare nod conține unele date și legătura sau referința altor noduri care pot fi numite copii.
Câțiva termeni de bază utilizați în structura de date Tree.
Să luăm în considerare structura arborelui, care este prezentată mai jos:

În structura de mai sus, fiecare nod este etichetat cu un număr. Fiecare săgeată prezentată în figura de mai sus este cunoscută ca a legătură între cele două noduri.
Proprietățile structurii de date arbore

Pe baza proprietăților structurii de date Tree, arborii sunt clasificați în diferite categorii.
actor rohit shetty
Implementarea Tree
Structura de date arborescentă poate fi creată prin crearea dinamică a nodurilor cu ajutorul pointerilor. Arborele din memorie poate fi reprezentat după cum se arată mai jos:

Figura de mai sus arată reprezentarea structurii de date arborescente în memorie. În structura de mai sus, nodul conține trei câmpuri. Al doilea câmp stochează datele; primul câmp stochează adresa copilului din stânga, iar al treilea câmp stochează adresa copilului din dreapta.
În programare, structura unui nod poate fi definită astfel:
struct node { int data; struct node *left; struct node *right; } Structura de mai sus poate fi definită numai pentru arborii binari, deoarece arborele binar poate avea cel mult doi copii, iar arborii generici pot avea mai mult de doi copii. Structura nodului pentru arbori generici ar fi diferită în comparație cu arborele binar.
Aplicații ale arborilor
Următoarele sunt aplicațiile arborilor:
Tipuri de structură de date arbore
Următoarele sunt tipurile unei structuri de date arborescente:

Poate fi n numărul de subarbori dintr-un arbore general. În arborele general, subarborele sunt neordonate, deoarece nodurile din subarborele nu pot fi ordonate.
Fiecare arbore negol are o margine descendentă, iar aceste margini sunt conectate la nodurile cunoscute ca nodurile copil . Nodul rădăcină este etichetat cu nivelul 0. Nodurile care au același părinte sunt cunoscute ca fratii .

Pentru a afla mai multe despre arborele binar, faceți clic pe linkul de mai jos:
https://www.javatpoint.com/binary-tree
Fiecare nod din subarborele din stânga trebuie să conțină o valoare mai mică decât valoarea nodului rădăcină, iar valoarea fiecărui nod din subarborele din dreapta trebuie să fie mai mare decât valoarea nodului rădăcină.
Un nod poate fi creat cu ajutorul unui tip de date definit de utilizator cunoscut ca structura, așa cum se arată mai jos:
struct node { int data; struct node *left; struct node *right; } Mai sus este structura nodului cu trei câmpuri: câmp de date, al doilea câmp este indicatorul din stânga al tipului de nod, iar al treilea câmp este indicatorul din dreapta al tipului de nod.
Pentru a afla mai multe despre arborele binar de căutare, faceți clic pe linkul de mai jos:
https://www.javatpoint.com/binary-search-tree
Este unul dintre tipurile de arbore binar, sau putem spune că este o variantă a arborelui de căutare binar. Arborele AVL satisface proprietatea arbore binar precum și al arbore binar de căutare . Este un arbore de căutare binar cu auto-echilibrare care a fost inventat de Adelson Velsky Lindas . Aici, auto-echilibrarea înseamnă că echilibrarea înălțimii subarborelui din stânga și subarborelui din dreapta. Această echilibrare este măsurată în termeni de factor de echilibrare .
Putem considera un arbore ca un arbore AVL dacă arborele respectă arborele de căutare binar, precum și un factor de echilibrare. Factorul de echilibrare poate fi definit ca diferența dintre înălțimea subarborelui din stânga și înălțimea subarborelui din dreapta . Valoarea factorului de echilibrare trebuie să fie 0, -1 sau 1; prin urmare, fiecare nod din arborele AVL ar trebui să aibă valoarea factorului de echilibrare fie ca 0, -1 sau 1.
imagini de reducere
Pentru a afla mai multe despre arborele AVL, faceți clic pe linkul de mai jos:
https://www.javatpoint.com/avl-tree
Arborele roșu-negru este arborele binar de căutare. Condiția prealabilă a arborelui roșu-negru este că ar trebui să știm despre arborele binar de căutare. Într-un arbore de căutare binar, valoarea subarborelui din stânga ar trebui să fie mai mică decât valoarea acelui nod, iar valoarea subarborelui din dreapta ar trebui să fie mai mare decât valoarea nodului respectiv. După cum știm că complexitatea de timp a căutării binare în cazul mediu este log2n, cel mai bun caz este O(1), iar cel mai rău caz este O(n).
Când se efectuează orice operație asupra arborelui, dorim ca arborele nostru să fie echilibrat, astfel încât toate operațiunile precum căutarea, inserarea, ștergerea etc., să dureze mai puțin și toate aceste operațiuni vor avea complexitatea de timp de Buturuga2n.
Arborele roșu-negru este un arbore de căutare binar cu auto-echilibrare. Arborele AVL este, de asemenea, un arbore de căutare binar de echilibrare a înălțimii de ce avem nevoie de un copac roșu-negru . În arborele AVL, nu știm câte rotații ar fi necesare pentru a echilibra arborele, dar în arborele Roșu-negru sunt necesare maximum 2 rotații pentru a echilibra arborele. Conține un bit suplimentar care reprezintă fie culoarea roșie, fie culoarea neagră a unui nod pentru a asigura echilibrarea arborelui.
Structura de date a arborelui splay este, de asemenea, arbore de căutare binar în care elementul recent accesat este plasat la poziția rădăcină a arborelui prin efectuarea unor operații de rotație. Aici, întinderea înseamnă nodul accesat recent. Este un autoechilibrare arborele de căutare binar care nu are nicio condiție de echilibru explicită, cum ar fi AVL copac.
Ar putea fi o posibilitate ca înălțimea arborelui splay să nu fie echilibrată, adică înălțimea ambelor sub-arbori din stânga și din dreapta poate diferi, dar operațiunile din arborele splay sunt în ordinea de calm timp unde n este numărul de noduri.
Arborele Splay este un arbore echilibrat dar nu poate fi considerat ca un arbore echilibrat in inaltime deoarece dupa fiecare operatie se efectueaza rotatie care duce la un arbore echilibrat.
Structura de date Treap provine din structura de date Tree și Heap. Deci, cuprinde proprietățile structurilor de date arbore și heap. În arborele de căutare binar, fiecare nod din subarborele din stânga trebuie să fie egal sau mai mic decât valoarea nodului rădăcină și fiecare nod din subarborele din dreapta trebuie să fie egal sau mai mare decât valoarea nodului rădăcină. În structura de date heap, atât subarborele din dreapta cât și din stânga conțin chei mai mari decât rădăcina; prin urmare, putem spune că nodul rădăcină conține cea mai mică valoare.
În structura de date treap, fiecare nod are ambele cheie și prioritate unde cheia este derivată din arborele de căutare binar și prioritatea este derivată din structura de date heap.
The Treap Structura datelor urmează două proprietăți care sunt prezentate mai jos:
- Fiul drept al unui nod>=nodul curent și copilul stâng al unui nod<=current node (binary tree)< li>
- Copiii oricărui subarbore trebuie să fie mai mari decât nodul (heap)
B-tree este echilibrat m-mod copac unde m definește ordinea arborelui. Până acum, am citit că nodul conține o singură cheie, dar b-tree poate avea mai mult de o cheie și mai mult de 2 copii. Menține întotdeauna datele sortate. În arborele binar, este posibil ca nodurile frunzelor să fie la niveluri diferite, dar în arborele b, toate nodurile frunzei trebuie să fie la același nivel.
Dacă ordinea este m, atunci nodul are următoarele proprietăți:
- Fiecare nod dintr-un arbore b poate avea maxim m copii
- Pentru copii minimi, un nod frunză are 0 copii, nodul rădăcină are minim 2 copii și nodul intern are plafon minim de m/2 copii. De exemplu, valoarea lui m este 5 ceea ce înseamnă că un nod poate avea 5 copii, iar nodurile interne pot conține maximum 3 copii.
- Fiecare nod are maxim (m-1) chei.
Nodul rădăcină trebuie să conțină cel puțin 1 cheie și toate celelalte noduri trebuie să conțină cel puțin plafon de m/2 minus 1 chei.