Python este un limbaj excelent pentru analiza datelor, în primul rând datorită ecosistemului fantastic de date centrate Piton pachete. panda este unul dintre acele pachete și facilitează mult importarea și analiza datelor.
Pandas DataFrame înseamnă()
panda dataframe.mean() funcția returnează media valorilor pentru axa solicitată. Dacă metoda este aplicată pe un obiect din seria panda, atunci metoda returnează o valoare scalară care este valoarea medie a tuturor observațiilor din Pandas Dataframe . Dacă metoda este aplicată pe un obiect Pandas Dataframe, atunci metoda returnează a Seria panda obiect care conține media valorilor peste axa specificată.
Sintaxă: DataFrame.mean(axis=0, skipna=True, level=None, numeric_only=False, **kwargs)
Parametri:
- axa: {index (0), coloane (1)}
- Ordin : Excludeți valorile NA/nule atunci când calculați rezultatul
- nivel: Dacă axa este un MultiIndex (ierarhic), numărați de-a lungul unui anumit nivel, prăbușindu-se într-o serie
- numai_numeric : Includeți numai coloane float, int, boolean. Dacă Nici unul, va încerca să folosească totul, atunci utilizați numai date numerice. Nu este implementat pentru serie.
Se intoarce : înseamnă: Series sau DataFrame (dacă este specificat nivelul)
dfs vs bfs
Pandas DataFrame.mean() Exemple
Exemplul 1:
Utilizați funcția mean() pentru a găsi media tuturor observațiilor pe axa indexului.
Piton # importing pandas as pd import pandas as pd # Creating the dataframe df = pd.DataFrame({'A':[12, 4, 5, 44, 1], 'B':[5, 2, 54, 3, 2], 'C':[20, 16, 7, 3, 8], 'D':[14, 3, 17, 2, 6]}) # Print the dataframe df> 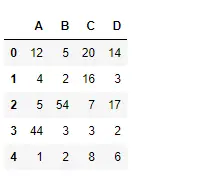
Să folosim funcția Dataframe.mean() pentru a găsi media peste axa indexului.
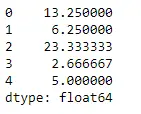
Piton # Even if we do not specify axis = 0, # the method will return the mean over # the index axis by default df.mean(axis = 0)>
Ieșire:
Exemplul 2:
Utilizați funcția mean() pe un Dataframe care are valori None. De asemenea, găsiți media peste axa coloanei.
Piton # importing pandas as pd import pandas as pd # Creating the dataframe df = pd.DataFrame({'A':[12, 4, 5, None, 1], 'B':[7, 2, 54, 3, None], 'C':[20, 16, 11, 3, 8], 'D':[14, 3, None, 2, 6]}) # skip the Na values while finding the mean df.mean(axis = 1, skipna = True)> Ieșire: