Comanda Linux uniq este folosită pentru a elimina toate liniile repetate dintr-un fișier. De asemenea, poate fi folosit pentru a afișa un număr de orice cuvânt, numai linii repetate, pentru a ignora caractere și pentru a compara anumite câmpuri. Este una dintre comenzile cele mai des folosite în Linux-ul sistem. Este adesea folosit cu comanda sortare deoarece compară caracterele adiacente. Îndepărtează toate liniile identice și scrie rezultatul.
Sintaxă:
uniq [OPTION]... [INPUT [OUTPUT]]
Opțiuni:
Câteva opțiuni utile pentru linia de comandă ale comenzii uniq sunt următoarele:
-c, --count: prefixează liniile după numărul de apariții.
sortarea tuplurilor python
-d, --repetat: este folosit pentru a tipări linii duplicate, câte una pentru fiecare grup.
-D: Este folosit pentru a tipări toate liniile duplicate.
--toate-repetate[=METODA]: Este destul de asemănător cu opțiunea „-D”, diferența dintre ambele opțiuni este că permite separarea grupurilor cu o linie goală.
-f, --skip-fields=N: Este folosit pentru a evita compararea primelor N câmpuri.
--grup[=METODA]: Este folosit pentru a afișa toate articolele și separă grupurile cu o linie goală.
-i, --ignore-case: Este folosit pentru a ignora diferențele în timpul comparării.
-s, --skip-chars=N: Este folosit pentru a evita compararea primelor N caractere.
-u, --unique: este folosit pentru a imprima linii unice.
-z, --zero-terminat: Este folosit pentru că delimitătorul de linie este NUL și nu modul newline.
npm șterge memoria cache
-w, --check-chars=N: Este folosit pentru a compara nu mai mult de N caractere în rânduri.
--Ajutor: Este folosit pentru a afișa documentația de ajutor.
--versiune: Este folosit pentru a afișa informațiile despre versiune.
Exemple de comandă uniq
Să vedem următoarele exemple ale comenzii uniq:
- Eliminați liniile repetate
- numărați numărul de apariții ale unui cuvânt
- Afișați liniile repetate
- Afișați liniile unice
- Ignorați caracterele în comparație
- Ignorați câmpurile în comparație
Eliminați liniile repetate
Pentru a elimina linii repetate dintr-un fișier, executați comanda de bază uniq după cum urmează:
sort dupli.txt | uniq
Comanda de mai sus va elimina liniile duplicate din fișierul „dupli.txt”. Luați în considerare rezultatul de mai jos:
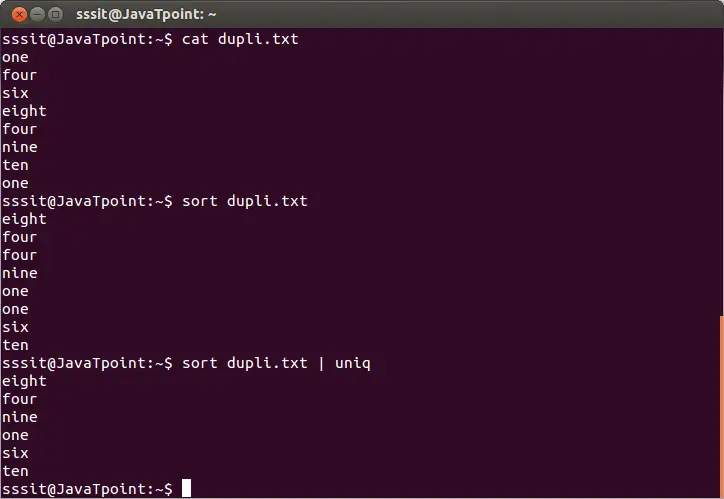
Din rezultatul de mai sus, cuvintele care se repetă sunt ignorate.
Numărați numărul de apariții ale unui cuvânt
Putem număra numărul de apariții ale unui cuvânt folosind comanda uniq. Opțiunea „-c” este folosită pentru a număra cuvântul. Execută-l după cum urmează:
sort dupli.txt | uniq -c
Comanda de mai sus va număra cuvintele care vin în „dupli.txt”. Luați în considerare rezultatul de mai jos:

Din rezultatul de mai sus, comanda „sort dupli.txt | uniq -c' numără de câte ori se repetă un cuvânt.
Afișați liniile repetate
Opțiunea „-d” este folosită pentru a afișa doar liniile repetate. Acesta va afișa doar liniile care vor fi de mai multe ori într-un fișier și va scrie rezultatul în ieșirea standard. Luați în considerare comanda de mai jos:
sort dupli.txt | uniq -d
Comanda de mai sus va afișa doar liniile repetate. Luați în considerare rezultatul de mai jos:

Afișați liniile unice
Opțiunea „-u” este folosită pentru a afișa doar liniile unice (care nu sunt repetate). Acesta va afișa doar liniile care apar o singură dată și va scrie rezultatul în ieșirea standard. Luați în considerare comanda de mai jos:
sort dupli.txt | uniq -u
Comanda de mai sus va afișa numai liniile unice din fișierul „dupli.txt”. Luați în considerare rezultatul de mai jos:
structură de date

Ignorați caracterele în comparație
Opțiunea „-s” este folosită pentru a ignora caracterele în comparație. Va ignora numărul specificat de caractere și va afișa rezultatul la ieșirea standard. Luați în considerare comanda de mai jos:
sort dupli.txt | uniq -s 2
Comanda de mai sus va ignora primele două caractere în comparație din fișierul „dupli.txt”. Luați în considerare rezultatul de mai jos:

Ignorați câmpurile în comparație
Opțiunea „-f” este folosită pentru a ignora câmpurile. Luați în considerare comanda de mai jos:
uniq -f 2 dupli2.txt
Comanda de mai sus nu va compara primele două câmpuri din fișierul „dupli2.txt”. Luați în considerare rezultatul de mai jos:

Din rezultatul de mai sus, primele două câmpuri sunt omise, iar restul tuturor câmpurilor sunt comparate din fișierul „dupli2.txt”.