După cum știm, algoritmul de învățare automată supravegheată poate fi clasificat în linii mari în algoritmi de regresie și clasificare. În algoritmii de regresie, am prezis rezultatul pentru valori continue, dar pentru a prezice valorile categoriale, avem nevoie de algoritmi de clasificare.
Ce este algoritmul de clasificare?
Algoritmul de clasificare este o tehnică de învățare supravegheată care este utilizată pentru a identifica categoria de observații noi pe baza datelor de antrenament. În Clasificare, un program învață din setul de date sau observațiile date și apoi clasifică observația nouă într-un număr de clase sau grupuri. Ca, Da sau Nu, 0 sau 1, Spam sau Nu Spam, pisică sau câine, etc. Clasele pot fi numite ca ținte/etichete sau categorii.
algoritmul rr
Spre deosebire de regresie, variabila de ieșire a clasificării este o categorie, nu o valoare, cum ar fi „Verde sau Albastru”, „fructe sau animal”, etc. Deoarece algoritmul de clasificare este o tehnică de învățare supravegheată, deci ia date de intrare etichetate, care înseamnă că conține intrare cu ieșirea corespunzătoare.
În algoritmul de clasificare, o funcție de ieșire discretă (y) este mapată la variabila de intrare (x).
y=f(x), where y = categorical output
Cel mai bun exemplu de algoritm de clasificare ML este Detector de spam prin e-mail .
Scopul principal al algoritmului de clasificare este de a identifica categoria unui set de date dat, iar acești algoritmi sunt utilizați în principal pentru a prezice rezultatul pentru datele categoriale.
Algoritmii de clasificare pot fi înțeleși mai bine folosind diagrama de mai jos. În diagrama de mai jos, există două clase, clasa A și clasa B. Aceste clase au caracteristici care sunt similare între ele și diferite de alte clase.
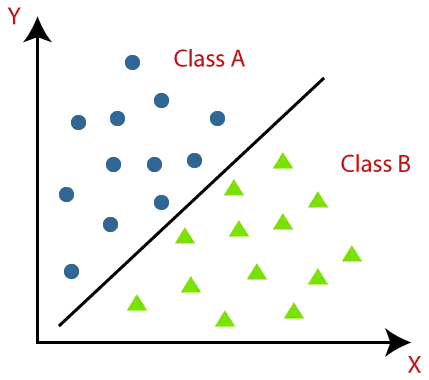
Algoritmul care implementează clasificarea pe un set de date este cunoscut sub numele de clasificator. Există două tipuri de clasificări:
Exemple: DA sau NU, BĂRBAȚI sau FEMEI, SPAM sau NU SPAM, PISICĂ sau CÂINE etc.
Exemplu: Clasificarea tipurilor de culturi, Clasificarea tipurilor de muzică.
Cursanți în probleme de clasificare:
În problemele de clasificare, există două tipuri de cursanți:
returnând o matrice java
Exemplu: Algoritm K-NN, Raționament bazat pe caz
Tipuri de algoritmi de clasificare ML:
Algoritmii de clasificare pot fi împărțiți în continuare în două categorii:
- Regresie logistică
- Suport mașini vectoriale
- K-Cei mai apropiati vecini
- Kernel SVM
- Nave Bayes
- Clasificarea arborelui de decizie
- Clasificare aleatorie a pădurilor
Notă: Vom afla algoritmii de mai sus în capitolele ulterioare.
Evaluarea unui model de clasificare:
Odată finalizat modelul nostru, este necesar să-i evaluăm performanța; fie este un model de clasificare sau regresie. Deci, pentru evaluarea unui model de clasificare, avem următoarele moduri:
1. Pierdere de log sau pierdere de entropie încrucișată:
- Este folosit pentru evaluarea performanței unui clasificator, a cărui ieșire este o valoare de probabilitate între 0 și 1.
- Pentru un model de clasificare binar bun, valoarea pierderii în log ar trebui să fie aproape de 0.
- Valoarea pierderii în log crește dacă valoarea estimată se abate de la valoarea reală.
- Pierderea mai mică în log reprezintă acuratețea mai mare a modelului.
- Pentru clasificarea binară, entropia încrucișată poate fi calculată ca:
?(ylog(p)+(1?y)log(1?p))
Unde y = ieșire reală, p = ieșire estimată.
2. Matricea confuziei:
- Matricea de confuzie ne oferă o matrice/tabel ca rezultat și descrie performanța modelului.
- Este cunoscută și sub numele de matricea erorilor.
- Matricea constă în rezultatul predicțiilor într-o formă rezumată, care are un număr total de predicții corecte și predicții incorecte. Matricea arată ca în tabelul de mai jos:
| Pozitiv real | Negativ real | |
|---|---|---|
| Pozitiv prezis | Adevărat pozitiv | Fals pozitiv |
| Negativ prezis | Fals Negativ | Adevărat negativ |

3. Curba AUC-ROC:
- curba ROC înseamnă Curba caracteristicilor de funcționare a receptorului iar AUC înseamnă Zona sub curbă .
- Este un grafic care arată performanța modelului de clasificare la diferite praguri.
- Pentru a vizualiza performanța modelului de clasificare multiclasă, folosim curba AUC-ROC.
- Curba ROC este reprezentată cu TPR și FPR, unde TPR (True Positive Rate) pe axa Y și FPR (False Positive Rate) pe axa X.
Cazuri de utilizare ale algoritmilor de clasificare
Algoritmii de clasificare pot fi utilizați în diferite locuri. Mai jos sunt câteva cazuri de utilizare populare ale algoritmilor de clasificare:
- Detectarea spam-ului prin e-mail
- Recunoaștere a vorbirii
- Identificarea celulelor tumorale canceroase.
- Clasificarea medicamentelor
- Identificarea biometrică etc.